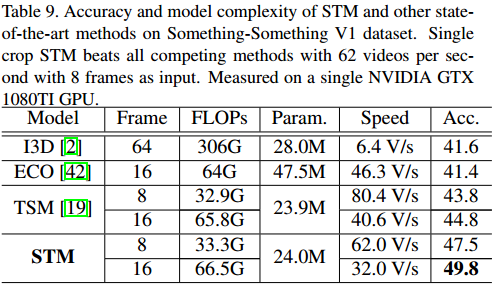
动作识别中最重要的特征是时空特征和运动特征,前者编码不同时间步空间特征的关系,后者表示相邻帧的运动特征。双流网络中的flow stream其实并不是时序stream,因为光流只表示相邻帧的运动信息,且stream的结构与空间stream几乎一模一样,因此,缺少获取长时时序关系的能力,而且光流的提取在时间和空间上的消耗都比较大,限制了其在现实世界的应用。另一种3D CNN的方法能直接从RGB的输入中建模时空信息,但是许多方法仍集成独立的光流运动stream来进一步提升性能,因此这两种特征在动作识别中是互补的,但是,将卷积核从2D变成3D、双流结构都不可避免地增加了一个数量级的计算消耗。基于以上分析,本文提出了一个简单但是有效的模型——STM网络,在一个统一的2D CNN网络中集成时空和运动特征,没有3D卷积和光流预计算。给定一个feature map,我们采用一个Channel-wise Spatiotemporal Module (CSTM)来表示时空特征,用Channel-wise Motion Module (CMM)来编码运动特征,并插入一个identity映射路径来组合两种特征,从而得到一个STM block。STM block可以轻易地插入到ResNet中,替换原来的残差快,增加的参数少到可以忽略不计,下图中我们可视化了带有CSTM和CMM特征的STM block,CSTM学习时空特征,相比于原来的特征,更多地聚焦于动作交互的主要的个体部分,CMM获取运动特征,就像光流一样。
STM网络
Channel-wise SpatioTemporal Module
下图所示,给定输入的feature map F(属于RN*T*C*H*W),说先对F进行reshapeF->F*(属于RNHW*C*T),然后在T维度使用channel-wise的1D卷积来融合时序信息,这里使用channel-wise而不是普通卷积id优点有两个:对于F*,不同通道的语义信息是完全不同的,不同通道时序信息的组合应该不一样,所以使用channel-wise的卷积来为每个通道学习独立的核;与普通卷积操作相比,可以降低比例G的计算消耗,G是组的数量,在我们的设置中,G等于输入通道的数量。channel-wise的时序融合操作可以用如下公式表示,其中K是属于通道c的时序组合中第i个时序kernel的的核权重,F*是输入的特征序列,G是更新之后的channel-wise时序融合特征,这里时序kernel的尺寸设置为3,所以i的取值为[-1,1]。然后将G reshape成原始输入的shape,[N,T,C,H,W],通过3*3的2D卷积建模局部空间信息。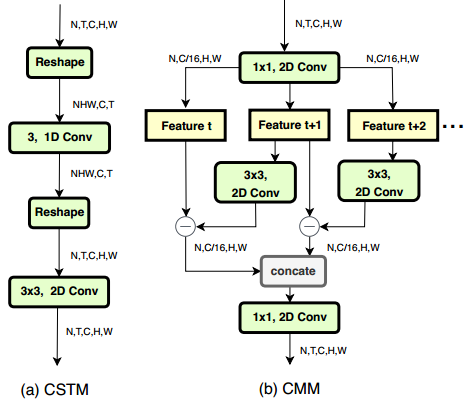
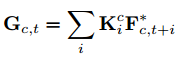
Channel-wise Motion Module
本文提出一个轻量的CMM来提取feature-level的运动特征,我们的目标是找到能帮助识别动作的运动表示,而不是两帧之间确切的运动信息(光流),所以我们只用RGB帧,不包含任何的预计算。给定输入的feature map,F,首先使用纪念馆1*1卷积来减少比例为r的特征通道,来减少计算消耗,实验中r=16,然后每两帧生成feature-level的运动信息,以Ft和Ft+1为例,首先使用对Ft+1进行2D的channel-wise的卷积,然后减去Ft来得到近似的运动表示Ht,如下所示,K表示第c个运动filter,i、j表示kernel的空间索引,这里kernel size设置为3*3,所以i, j的取值为[-1,1]。如上图b所示,我们在时序维度,对相邻的两帧进行CMM,也就是Ft与Ft+1,Ft+1与Ft+2,所以CMM会产生T-1个运动表示,为了将时序特征的尺寸与输入的feature map兼容,使用零值来表示最后时间步的运动信息,然后沿着时序通道合并,最后,用另外一个1*1的2D卷积来将通道数重置为C。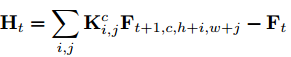
STM网络
为了使网络有效并且轻量,我们将CSTM和CMM组合来构建一个STM block,使其既能编码时空特征,也能编码运动特征,并且能轻易插入现有的ResNet中,整个网络的设计如下图下半部分所示,第一个1*1的2D卷积是用来减少通道维度,压缩之后的feature map输入到CSTM和CMM中来提取响应的特征,这里组合不同类型信息的方法有两种:求和和串接,实验中发现第一种方法效果优于第二种,所以在CSTM和CMM之后使用element-wise的和来集成信息,然后使用1*1的2D卷积来通道的维度,并且添加输入到输出的identity shortcut。整个STM网络的结构如上图的上半部分所示,使用ResNet-50作为backbone,将残差块都替换成STM block。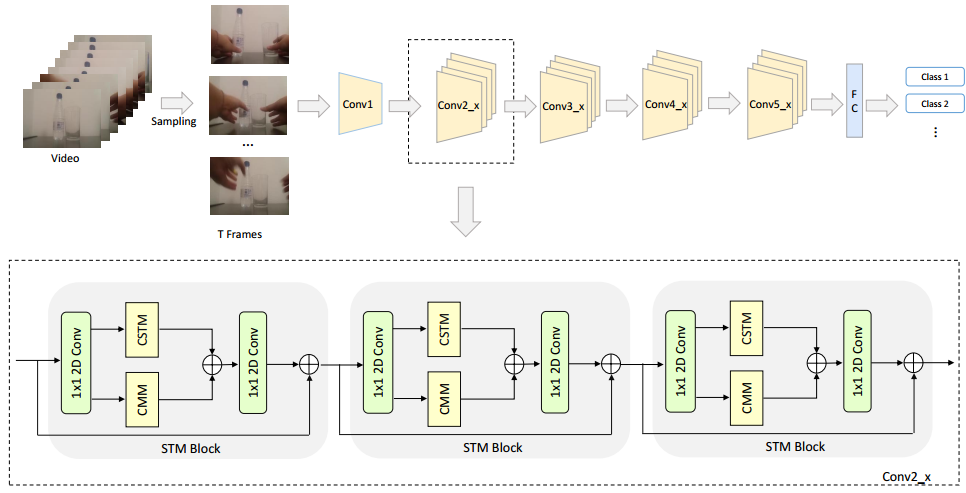
实验
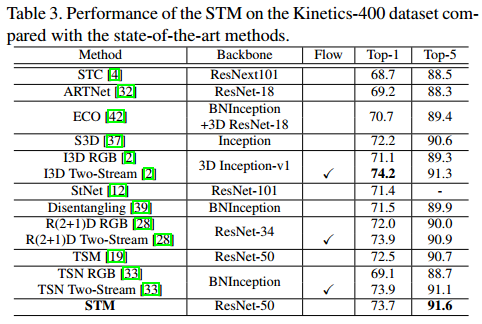
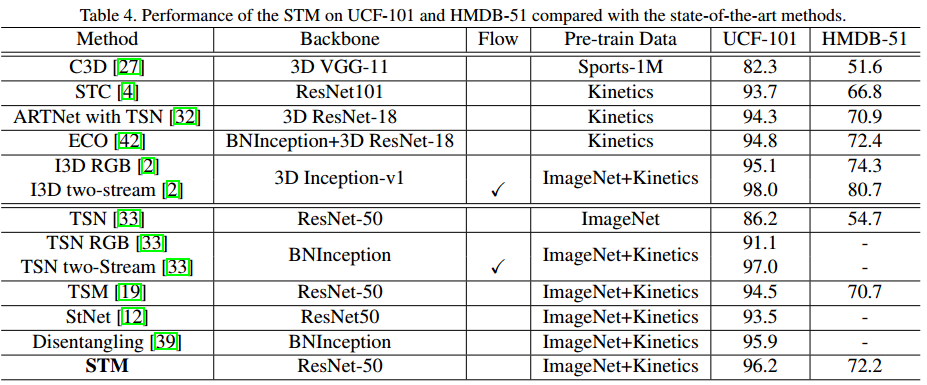
实验中用到的baseline是TSN,backbone为ResNet-50。
数据库
实验中用到的数据库分为两种:时序相关的数据库,包括Something-Something v1 & v2和Jester,个体间的时序运动交互是动作理解的关键,大部分动作可以在不考虑时序关系的情况下识别出来;场景相关的数据库,包括Kinetics-400、UCF-101和HMDB-51,在确定动作标签时,背景信息占了很大比例的作用,时序关系不像第一种数据库那么重要,下图也展示了他们的不同。因为本文的方法是用于高效的时空融合和运动信息提取,所以我们主要关注时序相关的数据库,当然场景相关的数据库也是获得了较好的表现。
实现细节
使用与TSN相同的方法训练STM,给定输入视频,先将其分成T个时长相同的segment,来获取长时时序结构建模,然后从每个segment中随机采样一帧,从而得到T帧的输入序列,尺寸固定为256,同事进行corner crop和scale-jittering来进行数据增广,最后将cropped的区域resize为224*224用于网络的训练,所以网络的输入为N*T*3*224*224,T是每个视频采样的帧数,在实验中为8或16。
模型巡礼啊你是在8个GTX 1080TI上,每个GPU处理mini-batch=8个视频clip(当T=8时)或者4个视频clip(当T=16时),Kinetics、Something-Something v1 & v2和Jester的初始学习率为0.01,在30、40、45个epoch时除以10,并在50个epoch时停止训练,对于这些大规模数据库,我们只使用ImageNet预训练的模型作为初始化,对于CSTM中的时序channel-wise的1D卷积,通道的前四分之一初始化为[1,0,0],通道的后四分之一初始化为[0,0,1],另一半为[0,1,0 ];CMM中的所有参数是随机初始化的。对于UCF-101和HMDB-51,我们使用Kinetics预训练的模型作为初始化,初始学习率为0.001,25个epoch,每15个epoch除以10,不同的是,在训练时开放所有的BN层。
在测试阶段,首先将视频片段resize为256,并取256*256的三个crop来覆盖空间维度,然后将其resize为224*224,时序领域,从全时长视频中随机采样10倍,计算各自的softmax分数,最终的预测是通过平均化所有的clip得到的。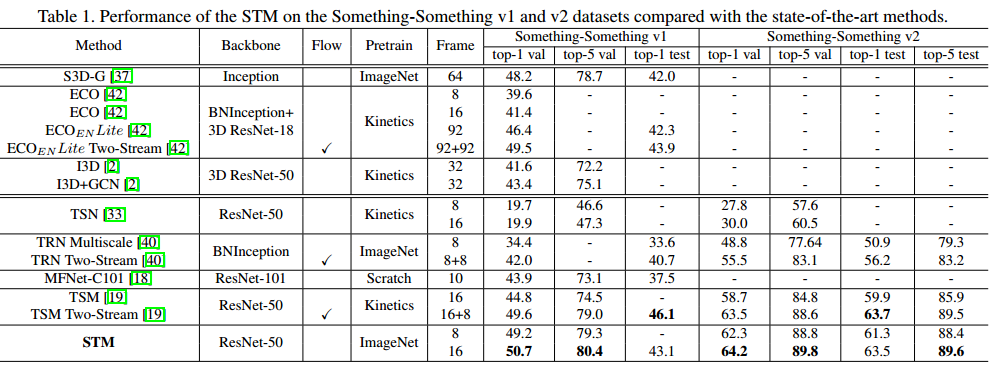

Ablation Studies
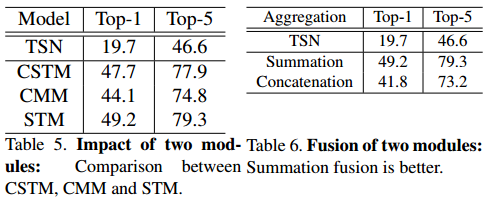
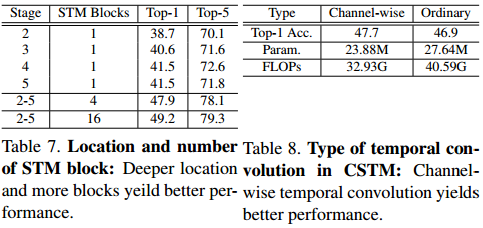
本文提出的模型可以独立地插入到ResNet中,为了验证STM block每个模块的作用,进行了实验;此外,还对插入ResNet的位置和插入的数量进行了实验,将conv2_x到conv5_x称为stage2-stage5,结果显示插入stage5的结果比插入早期,比如stage2的结果好,可能的原因是时序建模能更多地从能捕捉整体信息,有更大感受野的高层受益,而同时替换四个block的结果是更好的,当替换全部16个block的结果是最好的;另外,还测试了使用channel-wise和使用普通时序卷积在CSTM模块的效果,以上实验的实验结果如下所示。