本文提出了一种基于骨架的动作识别方法,Attention Enhanced Graph Convolutional LSTM Network (AGC-LSTM),不仅能提取空间和时间的判别性特征,而且能探索其中的相互关系;还提出了一种时序分级结构来增加模型顶层的时序感受野,提高学习高级语义表示的能力,而且减少计算量;另外,为了选择有判别性的空间信息,使用attention机制来增加每个层关键关节点的信息。
动作识别的方法有很多,有些是基于RGB视频,有些是基于3D骨架数据。基于RGB视频的方法主要是从RGB图像和光流数据中建模时空表示,但是这种方法在处理背景复杂、亮度变化和外观变化场景时会有局限性;3D骨架用一系列关键关节点的3D坐标位置来表示身体结构,尽管不包含颜色信息,但是没有RGB视频所受的那些限制,允许建模更有判别性的时序特点,而且有研究和实验(Visual perception of biological motion and a model for its analysis)表明关键关节点能提供人类动作的高度有效的信息,而且现在有很多算法能轻易获取到人的关节点数据。
人的骨架序列一般有三个特点,每个节点和与之相连的关节点之间强相关,骨架frame包含丰富的身体结构信息;时间上的连续性不仅存在于相同的关节(例如手,腕和肘部)中,而且还存在于身体结构中;时间和空间领域存在相互关系。
基于图的模型主要分为两种结构,一种为GNN (Graph Neural Network),是图和RNN的组合,经过节点的多次信息传递和状态更新,每个节点获取其相邻节点的语义关系和结构信息,可以用来检测和识别人机交互、环境识别;另一种结构是GCN (Graph Convolutional Network),将卷积神经网络扩展到图,一般有两种类型的GCN:spectral GCN和spatial GCN,第一种将图信号转换到图谱领域,并在频谱域应用频谱滤波器,比如依靠图的拉普拉斯在频谱领域使用CNN;另一种是基于卷积操作,使用每个节点及其相邻节点,计算一个新的特征向量
本文提出的AGC-LSTM模型如下图所示,首先将每个关节点的坐标用线性层转换成时空特征,然后将时空特征和每两个连续帧之间的特征差异组合,得到一个扩增的特征,然后用LSTM处理每个关节点序列,消除特征差异和位置特征之间的比例差异,接着使用三个AGC-LSTM层建模时空特征。计算具有位置特征的特征差异,并将位置特征和特征差异组合,LSTM用于消除特征差异和位置特征之间的比例差异,三个AGC-LSTM层可以建模时空特征。")
AGC-LSTM层的具体结构如下图所示,其内部的图卷积operator不仅能高效提取空间configuration和时序动态中的判别性特征,而且能探索时间空间领域的相互关系。另外,使用attention机制来增强每个时间步中关键关节点的特征,保证AGC-LSTM能学到更有判别性的特征,比如,肘、手腕和手的特征对于“挥手”的动作很重要,在识别动作时应该被突出。
模型结构
图卷积神经网络
GCN是一种通用的高效的学习图结构数据的表示方法,对于基于骨架的动作识别,用Gt={Vt, Et}表示时间t单帧图像上人的骨架的图,Vt是N个关节点的集合,Et是节点边的集合,节点vti的邻接点的组合表示为N(vti)={vtj|d(vti, vtj)<=D},其中d是表示从vtj到vti的最短路径长度,给图打标签的函数为l: Vt->{1,2,…K},加你个标签{1,2,…K}赋给每个图的节点vti(属于Vt),将vti的邻接点的集合N(vti)分成固定数量的K个子集,图卷积的计算方法一般如下所示,其中X(vtj)是节点vtj的特征,W是权重函数,从K个权重中分配一个由标签l(vtj)索引的权重,Zti(vtj)是对应的子集的数量,能归一化特征表示,Y表示图卷积在节点的输出。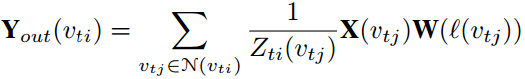
根据邻接矩阵的性质,上述公式可以写成如下形式,其中Ak是标签k(属于{1,2,…,K})在空间设置中的邻接矩阵,另一个变量为度矩阵,是邻接矩阵的求和,表示如下。
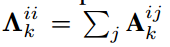
Attention Enhanced Graph Convolutional LSTM
LSTM能建模时序依赖,但是由于LSTM内部的全连接操作器,使得其忽略了基于骨架的动作识别的空间关联。与LSTM类似,AGC-LSTM也有三个门,但是是图卷积操作器,其输入Xt、Ht和cell memory Ct都是图结构的数据。下图展示了AGC-LSTM的结构,由于其内部的图卷积操作器,cell memory Ct和隐层状态Ht能展示时序动态,并且包含空间结构信息。
AGC-LSTM的公式如下所示,其中*G表示图卷积操作器,Wxi*GXt表示Xt的图卷积,权重为Wxi,可以用上述图卷积公式计算,输出Ht是attention和非attention的和,为了增强关键节点的信息而不削弱非聚焦节点的信息,从而保持空间信息的完整性。
attention机制是使用soft-attention的方式聚焦关键的关节点,空间attention网络的说明如下图所示。AGC-LSTM的隐层Ht包含丰富的空间结构信息和时序动态,有利于引导关键节点的选择,所以首先集成所有节点的信息作为query特征。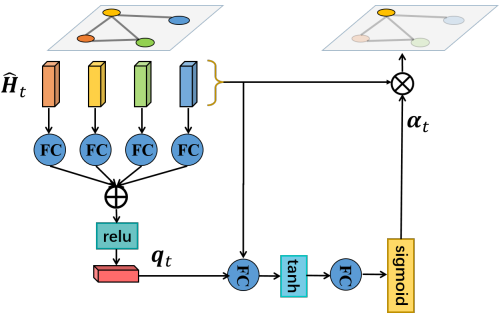

所有节点的attention分数可以按如下方式计算。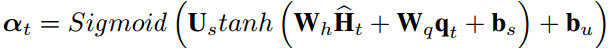
在最后一个AGC-LSTM层,所有节点特征的集合将作为全局特征Ftg,聚焦后的节点的加权和将作为局部特征Ftl,两个特征用来预测动作的类别。
AGC LSTM
关节特征表示方法
对于骨架序列,先使用线性层和LSTM层,将每个关节点的3D坐标映射到高维特征空间,线性层将坐标映射为256维的向量作为位置特征Pt,Pti表示关节点i的位置表示,由于其只包含位置信息,所以Pti有利于学习图模型中的空间结构特征,两个连续帧之间的帧差特征Vti可以促进动态信息的获取,为了考虑这两个优势,将两个特征串联作为扩增的特征,来丰富特征信息,但是在串联的过程中存在尺度差异,所以使用LSTM层来消除差异,如下所示,Eti表示节点i在时间t的扩增特征,不同节点共享线性层和LSTM层。
时序分级结构
经过LSTM层后,扩增的特征{E1,E2,…ET}会被输入到GC-LSTM层作为节点特征,其中Et属于RN*de,本文提出的模型堆叠了三个AGC-LSTM层来学习空间配置和时序动态,这里提出了一个时序分解结构,在时序领域进行avg-pooling来增加顶层AGC-LSTM层的感受野,从一帧变成一个短时的clip,对于时序动态的感知更加敏感,而且能减少计算消耗。
学习AGC-LSTM
全局特征Ftg和局部特征Ftl转换为C个类别的分数otg和otl,其中ot={ot1,ot2,…,otC},而属于某个类别的预测概率可以按如下方式表示。
在训练时,考虑到顶层AGC-LSTM层每个时间步的隐层状态包含了短时动态信息,我们用以下loss来对模型进行监督,y={y1,…,yC}是gt,Tj表示第j个AGC-LSTM层的时间步的数量,第三项是为了对不同的管IE点给予相同的attention,最后一项是为了限制感兴趣节点的数量,lambda和beta是权重衰减因子,只有最后时间步的概率的和才被用来预测动作类别。
尽管基于关节点的AGC-LSTM已经达到最好的效果,但是这里也探索了提出的模型在part level的效果,根据人的物理结构,身体可以分成7部分,类似于基于关节的AGC-LSTM网络,我们首先使用线性层和共享LSTM层来获取part的特征,然后将其作为节点表示,输入到三个AGC-LSTM中来建模时序特点,实验表明我们的模型能在part level获得更好的表现,基于关节和part的模型如下所示,能取得更好的效果。
实验
NTU RGB+D数据库
数据库包括60中动作,主要分成三个组:日常动作、交互动作和健康相关的动作,共40个独立个体,56880个动作样本,每个动作样本包括RGB视频,深度序列、3D骨架数据和三台微软Kinect v2摄像机同时拍摄的红外视频,3D骨架数据包括每一帧中25个关节点的3D位置,评估的Protool有两个:CrossSubject (CS)和Cross-View (CV),在CS中,20名受试者的动作构成训练集,其余20名受试者的动作用于测试;在CV中,前两个相机获取的样本用于训练,其余用于测试。
Northwestern-UCLA数据库
数据库包含10种动作,1494个视频片段,是用3个Kinect相机同时拍摄得到,每个动作样本包括RGBD和骨架数据,由10个独立个体完成,来自前两个相机的样本作为训练集,其他作为测试集。
实验细节
实验中,从每个骨架序列采样固定长度T的样本作为输入,两个数据库的T分别设置为100和50,在AGC-LSTM中,每个节点的邻接集合只包含一个直接连接的节点,所以D=1,三个AGC-LSTM层的通道为512,在训练时,使用0.5的dropout,初始学习率为0.0005,每20个epoch,学习率降为1/10,batch_size分别为64和30。





