当前的3D CNN的网络计算量比较大,而且相比于2D CNN,模型较大:如11层的C3D网络模型大小为321MB,而ResNet-152只有235MB。更重要的是,使用Sports-1M来finetuneResNet-152的效果,比从头开始训练C3D的效果好。另一种提取时空特征的方法是使用RNN,但这种方法只建立了高层的高级特征的时序联系,并没有使用低层的低级特征,如corner、edge等。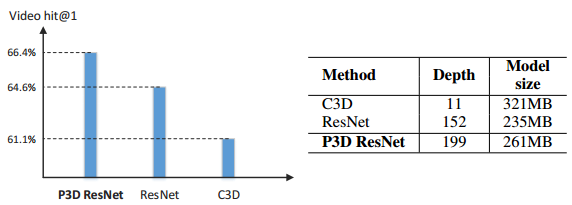
本文就是为了解决上述问题,将3D卷积解耦成2D空间卷积来编码空间信息和2D时序卷积,设计了bottleneck building blocks,每个block的核心模块是一个1*3*3和3*1*1卷积的组合,组合的方式为并列或者级联,来代替一个标准的3*3*3卷积,也成为伪3D卷积;比外,还提出了一个Pseudo-3D Residual Net (P3D ResNet)模型,整个网络类似ResNet的格式,并且由block组成。作者公开了Caffe版本的代码,其他还有复现的Pytorch版本和TensorFlow版本。
P3D blocks和P3D ResNet
残差网络:xt+1=h(xt)+F(xt),其中h(xt)是一个直接映射,F是一个非线性残差函数,所以公式也可以写成(I+F)*xt=xt+F*xt:=xt+F(xt)=xt+1,其中F*xt表示对xt直接运用残差函数F的结果。
给定视频,大小为c*l*h*w,分别表示channel、clip长度、高度和宽度,在搭建P3D模块时,类似残差块,但需要考虑,空间卷积和时间卷积是否应该直接或者间接影响对方,直接影响也就是用级联的方式,间接影响是Parallel的方式;另外,两个filter的输出是否应该直接影响最终的输出,直接影响表示每种类型的filter的输出应该直接与最终的输出相连。基于以上两个考虑,提出了三种P3D block的搭建方法,如下所示。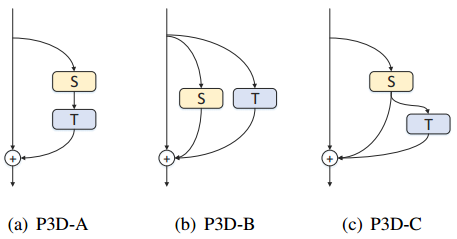
P3D-A:两种卷积直接互相影响,只有1D卷积直接与最终结果相连,公式表示为(I+T*S)*xt:=xt+T(s(xt))=xt+1
P3D-B:两个filter间接影响,使用Parallel的模式,两个filter的结果直接加到最终的输出中,公式表示为(I+S+T)*xt:=xt+S(xt)+T(xt)=xt+1
P3D-C:P3D-A和P3D-B的组合,同事构建S与T、与最终输出的直接影响,公式表示为(I+S+T*S)*xt:=xt+S(xt)+T(S(xt))=xt+1
2D残差模块是一个bottleneck的设计,来减少计算复杂度,如下图a所示,本文也使用类似的bottleneck设计,对于包含2D+1D卷积的模块,我们两个filter之后都添加了1*1*1的卷积层来升维和降维,如下图所示。
为了验证三个P3D block的优势,提出了三种基于ResNet-50的网络结构,完整版的P3D ResNet是将所有三个P3D block混合来实现的。首先,基于ResNet-50的网络结构的对比是在UCF-101上进行的,首先用UCF-101的视频数据来finetune ResNet-50,输入为从240*320上随机crop得到的224*224的图片,冻结了除第一个BN层之外的所有BN层的参数,并添加参数为0.9的dropout。finetune之后,网络会为每一帧预测一个分数,最终将所有帧的分数进行平均来得到video-levle的预测。除了额外的时序卷积,三个P3D ResNet的结构都是由ResNet-50初始化,然后在UCF-101上进行finetune,输入为16*160*160的视频clip,输入来源是从resized的无重叠的、分辨率为16*182*242的16帧clip上随机crop,每个帧/clip随机水平clip来进行数据增广,训练阶段的batch_size=128帧/clip,多个GPU并行训练,优化器为SGD,lr=0.001,每3k个迭代lr除以10,在7500个迭代后停止训练。模型对比的结果如下表所示。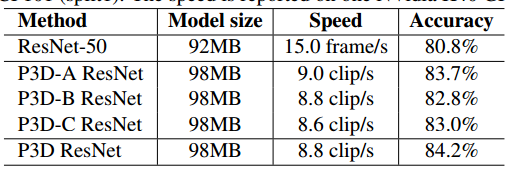
受启发于之前在设计很深的网络时,会追求结构的复杂度,本文通过混合不同的P3D block来搭建最终的P3D ResNet,如下图所示,将残差单元替换为P3D block组成的链。
时空表示学习
我们进一步验证P3D ResNet在更深的152层ResNet上的效果,然后生成一个通用的时空视频表示方法,P3D ResNet的学习是在Sports-1M上进行的,在下载时有一些URL无法访问,所以最终的100w个视频上进行试验,并以70%、10%和20%的比例分成三个集合。训练时,从每个视频中任意选择5个5秒的短视频,除dropout的比例设置为0.1外,其他设置与之前一致,学习率为0.001,每6w次迭代降为1/10,经过15w个batch后停止训练。测试时,从每个视频中随机采样20个clip,并对每个clip进行中心crop,输入到模型中得到clip-level的预测分数,通过平均所有的分数来得到video-level的预测。对比结果如下所示,此外,还使用DeepDraw工具来可视化学到的模型。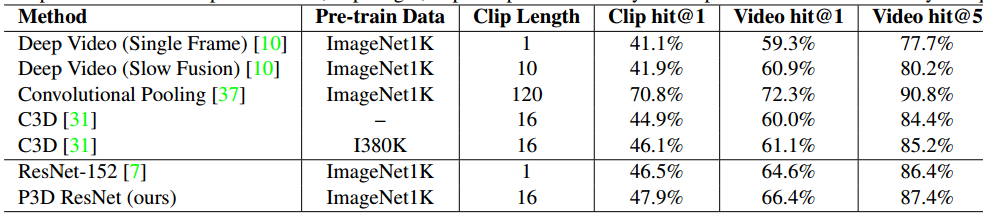

在Sports-1M上训练之后,模型可以当做通用的表示提取器,用在任一视频分析任务中,给定一个视频,我们选择20个clip,每个clip为16帧,输入到学习的P3D ResNet网络中,其中pool5层的2048维的激活值是这个clip的表示,最终所有clip-level的表示平均化来生成一个2048维度的表示。
视频表示的评估
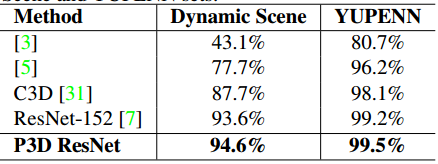
在上述提取视频表示后,可以在三个任务、五个数据库中评估其效果,包括UCF-101、ActivityNet、ASLAN、YUPENN、Dynamic Scene。分别对应动作识别(人的行为理解)、动作相似性标签和场景识别。UCF-101的方法可以分成三种:端到端的CNN结构、CNN特征提取+线性SVM和融合IDT的方法,而最近的端到端的CNN结构经常使用和融合两种或多种输入:帧、光流或者音频。对于动作相似性标签的任务,我们提取P3D ResNet的四个层的输出:prob、pool5、res5c和res4b35,作为对每个16帧的clip的四种类型的表示,通过对clip-level表示的平均化来得到最终video-level的表示,对于每对视频,我们计算12中相似度的值,所以生成了48维的向量,然后使用L2归一化和线性SVM的二分类分类器。


除以上对比外,还比较了在UCF-101上提取不同维度的视频表示的精度,在原始的IDT、ResNet-152、C3D和P3D ResNet上进行PCA,此外,还使用t-SNE来对学到的表示进行映射的可视化,从UCF-101中选择1w个视频,将video-level的表示映射到二维空间。

未来的工作包括,将attention机制加入到模型中;在训练时,增加每个clip的帧数,看看如何影响P3D ResNet的性能;使用不同的输入,如光流或音频。