卷积网络在静态图片的识别中取得了很大的成效,但是在动作识别中,相比于传统方法,优势并没有那么明显,本文探索了基于卷积神经网络的动作识别方法,尤其是在有限的训练样本的情况下,提出了时序分割网络(Temporal Segment Network, TSN),该方法是基于长时时序结构建模。本文的代码已经公开,有caffe版本)和Pytorch版本,有1、2、3篇博文是解读Pytorch版本的代码的。此外还公开了基于Pytorch的动作识别开源工具MMAction。
现有的方法多是在剪辑过的视频上进行试验,但是在实际中我们需要在没有剪辑过的视频(如THUMOS,ActivityNet)进行试验,每个动作可能只占整个视频的一小部分,主要的背景部分可能会干扰动作识别模型的预测。为了解决这个问题,我们需要考虑定位动作的位置,同时避免背景的影响。其次,训练动作识别模型时会遇到一些问题:训练深度卷积网络通常需要大量的训练样本才能达到最优的表现,但是现有公开的动作识别数据库,如UCF-101和HMDB51在规模和复杂度上都还很局限,模型容易过拟合;提取光流特征来获取短时运动信息成为了一个计算的瓶颈。所以,本文从以下几个方面着手:如何高效学习视频表示,从而提取长时时序结构;如何在实际的未剪辑视频中应用模型进行识别;在给定有限的训练样本的情况下如何有效地学习卷积网络,并将模型应用到大规模的数据中。
我们提出的TSN网络提供了一个简单并且通用的学习视频中动作模型的网络,这个模型是基于,我们观测到连续的视频帧是高度冗余的,稀疏并且全局的时序采样策略更适合并且更高效。TSN框架使用稀疏采样方案在较长的视频序列上提取短片段snippet,首先将视频划分为固定数量的分段segment,然后从每个片段中随机采样一个片段。之后,使用segmental consensus函数来集成采样的snippet中的信息,这样可以建模整个视频的长时时序结构,计算复杂度独立于视频长度,实际上,我们全面研究了不同段数的影响,并提出了五个集成函数来总结这些采样片段的预测分数,包括三种基本形式:average pooling, max pooling和加权平均,以及两个高级方案:top-K pooling和自适应attention加权。后面两个的设计是为了在训练时自动化突出有判别性的snippet。
为了将学习之后的模型应用到未剪辑视频,我们设计了一个分级集成策略,叫做M-TWI (Multi-scale Temporal Window Integration)。我们首先将未剪辑的视频分成固定时间的短时间窗的序列,然后为每个窗口独立地进行动作识别,窗口内的动作识别是通过max-pooling窗口中所有snippet-level的识别分数得到的,最终,通过时序segment网络的集成函数,我们使用top-K pooling法或attention权重来集成这些窗口的预测,从而得到video-level的识别结果。由于隐含选择有间隔的判别性动作的能力,同时能抑制噪声背景影响,本文提出的集成模型能有效识别未剪辑的视频。
为了解决有限数据库的问题,我们首先提出了一个交叉模式初始化方法,将从RGB模式学习到的representation转移到其他模型,如光流;其次,我们提出了一个在fine-tune场景中进行BN的策略,称为partial BM,只有第一个BN层的均值和方差需要自适应更新来控制domain shift。为了全面地使用视频中的视觉内容,我们研究了TSN的四种类型的输入模式,单帧RGB图像、堆叠RGB差异、堆叠光流场和堆叠warped optical flow fields。将RGB和RGB差异组合,我们构建了最好的实时动作识别系统,能解决现实生活中的很多问题。
本文的贡献点有三个:端到端的视频表示模型TSN,能获取长时时序信息;分级集成策略,在未剪辑的视频中进行动作识别;一系列学习和应用深度动作识别模型的好的实践。在之前论文的基础上,本文的扩展点有:TSN中新的集成函数,能有效突出重要的snippet同时减少背景噪声;通过设计分级集成策略,将原始的动作识别方法扩展到未剪辑视频的分类;对TSN网络进行进一步的探索研究,增加了两个数据库的实验;基于TSN网络,提出了ActivityNet挑战赛2016的解决方案,在未剪辑视频分类的24支队伍中排名第一。
TSN网络
以前学习长时时序结构的网络,由于计算量和GPU内存的限制,通常只能处理固定的64~120帧的序列,不太可能学习整个视频。而本文提出的方法没有序列长度的限制,是一个video-level的端到端的结构,能建模整个视频。
基于segment采样策略的来源
以双流网络和C3D为例的网络能操作有限的时序长度,如单帧或者帧的堆叠(如16帧),这些结构缺少将长时时序信息整合到动作模型的学习中的能力。为了建模长时时序结构,有很多方法,如堆叠更多的连续帧(如64帧)或者以固定比例采样更多的帧(如1FPS),尽管类似这种密集或局部采样的方法能帮助缓解双流和C3D这种短时卷积网络的问题,但依然存在计算量和建模方面的问题,从计算的角度说,这些方法会极大地增加卷积网络训练的计算量;从建模的角度说,这些方法的时序覆盖依旧是局部和有限的,如采样的64帧只占了一段10s视频(约300帧)的一小部分。
另外,尽管这些方法密集记录了视频帧,但是内容的改变却是相对缓慢的,于是我们提出了segment based sampling方法,这是一种稀疏和全局的采样方法,首先,只有一小部分稀疏采样的snippet会用来建模一个动作中的时序结构,通常一次训练迭代的采样帧的数量固定为一个预定义的值,这个值与视频长度无关,这能保证计算消耗是一个常数;其次,这个方法确保了这些采样的snippet会沿着时序维度均匀分布,因此无论动作视频持续多久,我们采样的snippet会一直大致覆盖整个视频的视觉内容。
网络结构
TSN网络的输入是一系列从整个视频中采样的短的snippet,为了使这些采样的snippet能表示整个视频的内容同时保持合理的计算量,segment based sampling方法会首先将视频分成几个等时长的segment,然后从每个segment中采样一个snippet,序列中每个snippet会生成snippet-level的动作类别预测,然后使用一个consensus函数将这些snippet-level的预测集成,并通过softmax得到video-level的分数,这个分数会比原始的snippet-level分数更可靠,因为获取了整个视频的长时信息,在训练阶段,优化目标是video-level的预测。在这里,consensus函数是很重要的,因为它应该具备高度建模能力,同时要可微分或者有子梯度,高度建模能力是指将snippet-level的预测集成为video-level的能力。整个网络结构如下图所示。
整个集成过程可以用如下公式表示,F(Tk; W)表示对短的snippet,即Tk进行预测的参数为W的卷积网络,会生成类别分数,G为consensus函数,预测函数H为整段视频预测类别,这里用的是softmax函数。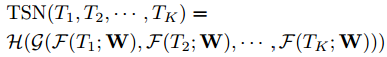
训练期间,结合标准的categorical cross-entropy,最终的损失函数如下所示,C是动作类别的数量,gj是G的第j个维度,G=G(F(T1;W), F(T2;W),…,F(TK;W))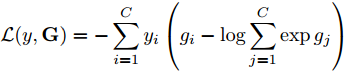
损失函数关于W的梯度如下所示,K是TSN网络中segment的数量,以下公式展现了参数更新使用了所有snippet-level的预测的segment consensus函数G,这样TSN网络就能用整个视频学习参数,而不是短的snippet。另外,通过为所有视频固定K,我们将稀疏的时序采样聚合来选择少量的snippet,另外,相比于使用密集采样的方法,这能极大地减少对视频帧进行evaluate的卷积网络的计算量。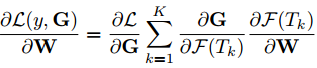
集成函数(consensus函数)
这里我们提出了五种consensus策略:max-pooling,average-pooling,top-K pooling,加权平均和attention加权。
Max-pooling
这种方法是对采样的snippet每个种类的预测分数进行max-pooling,即gi=maxk=1,2,…KfiK,其中fiK是Fk=F(Tk; W)的第i个元素,gi关于fiK的梯度为: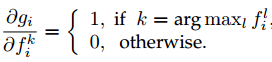
使用max-pooling的主要原理是为每个动作类别寻找一个最有判别性的snippet,并且使用这种最有力的激活作为video-level的响应,它强调单个snippet,完全忽略其他snippet的响应。所以,这种集成函数鼓励TSN从最有判别性的snippet学习,但是缺少将多个snippet联合建模成video-level动作识别的能力。
Average-pooling
对所有的K个fik求平均,梯度为1/K。这种方法对所有snippet的响应进行平均,使用均值作为video-level的预测值,这种方法联合建模了多个snippet,并且从整个视频中获取视觉信息;另外,对于一些背景复杂的有噪声的视频,一些snippet可能是与动作无关的,平均化这些背景snippet可能会影响最终的识别性能。
Top-K pooling
为了均衡max和average pooling,提出了top-K pooling,我们首先为每个动作种类选择K个最有判别性的snippet,然后平均化这些选择的snippet,公式和梯度可以如下表示,这个集成函数能自适应决定有判别性的snippet的子集,具备max和average两种方法的优势,能联合建模多个相关的snippet同时避免背景snippet的影响。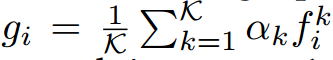
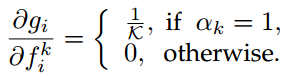
线性加权
这种方法是对每个动作类别的预测采用element-wise的加权线性组合,公式和梯度可以如下表示,wk是第k个snippet的权重,是自适应更新,这种集成方法的假设是动作可以分解成几个阶段,这些不同的阶段在识别中起到不同的作用,这个集成函数希望能学到一个动作类别不同阶段的权重,可以作为snippet选择的soft版本。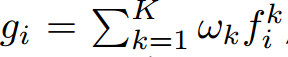
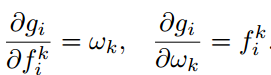
Attention加权
很明显线性加权是与数据独立的,缺少考虑视频之间差异的能力,因此又提出一种自适应加权的方法,attention加权,这种集成函数希望函数能根据视频内容为每个snippet自动分配一个重要性权重,公式表示和权重如下所示,A(TK)是snippet TK的attention权重,是根据视频内容自适应计算的,对最终的性能很重要。在当前的方法中,我们首先用相同的卷积网咯从每个snippet中提取视觉特征R = R(TK),然后生成attention权重A(TK)。其中wattn是attention权重计算函数的参数,可以和网络权重W一起学习,R(Tk)是第k个snippet的视觉特征,目前是最后隐层的激活值,那么A(Tk)关于wattn的梯度如下所示,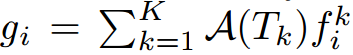
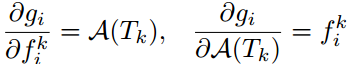
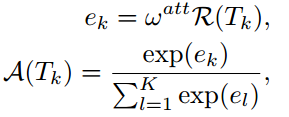
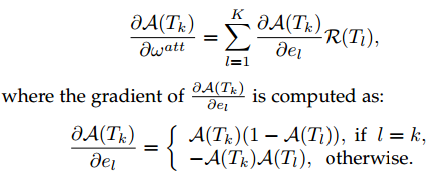
有了梯度计算公式后,我们可以与卷积网络参数W一起,通过反向传播学习attention建模参数wattn,而且,反向传播的公式可以按如下所示的方式定义。所以,这种方法的优势有两点:增强了基于视频内容自动学习每个snippet重要性的能力;由于attention模型是基于卷积网络的表示R,利用额外的反向传播信息指导ConvNet参数W的学习过程,可以加快训练的收敛速度。
实际的TSN网络
实际训练中为了使TSN网络达到最优性能,需要考虑一些训练技巧。
TSN结构
为了体现方法的通用性,用多种网络结构初始化TSN,为了进行多方面的验证,这里采用了Inception v2,因为这个结构平衡了精度和效率,在ActivityNet挑战赛中,我们探索了更强大的结构,包括Inception v3和ResNet152。
TSN输入
相比于图片,视频额外的时序维度携带了另一种用于动作理解的重要线索,也就是运动,双流网络中使用密集光流场作为输入证明是有效果的,在这篇文章中,我们从两个方面扩展了这个方法:精度和速度,如下图所示,除了原始的RGB和光流外,我们也探索了另外两种模式:warped optical flow fields和RGB差异。
warped optical flow fields
warped optical flow fields对相机的运动具有鲁棒性,能处理相机位移带来的水平方向位移的影响,帮助集中于人的动作,我们希望这有助于提高运动感知的准确性,从而提高动作识别性能。
RGB差异
双流网络虽然精度高,但影响其应用的问题是光流提取所消耗的时间,为了解决这个问题,我们构建了一个没有光流的运动表示方法,我们重新回顾了最简单的视觉运动感知线索:堆叠的连续帧之间的RGB像素差异。回顾之前的研究中关于密集光流的工作,像素强度与时间的偏导数在计算光流中起着关键作用,所以假设光流在表示运动特征方面的能力可以通过简单的RGB来学习是合理的。
TSN训练
现有的人类标注的动作识别数据库规模较小,在实际中使用这些数据库训练卷积网络很可能会过拟合,为了解决这个问题,我们设计了几种优化训练的策略。
交叉模式初始化
当目标数据库没有足够的训练样本时,在大规模图像识别数据库如ImageNet中预训练网络参数是有效的策略,因为空间网络以图片作为输入,所以很自然想到用ImageNet上预训练的模型作为初始化,对于其他输入模式,如光流和RGB差异,我们提出交叉模式初始化策略,首先通过线性变换的方法将光流离散化到[0, 255],然后在第一层,沿RGB通道平均化预训练的RGB模型的权重,并将平均值复制为时序网络的输入,最后时序网络余下层的权重直接从预训练RGB网络中复制。
正则化
BN层加速了训练时网络的收敛,同时,由于偏向于目标数据库有限规模训练样本的均值和方差,增加了迁移学习阶段过拟合的风险,因此,经过预训练模型初始化后,固定除了第一个BN层之外的所有BN层的均值和方差。由于光流的贡献不同于RGB图像,所以第一个卷积层的激活值会有不同的分布,并且我们需要重新评估对应的均值和方差,我们把这种策略称为partial BN,同时,我们在全局池化之后添加了额外的dropout层,dropout比例较高0.8,来进一步降低过拟合的影响。
数据增广
原始的双流网络使用随机crop和水平flip来扩增训练样本,这里我们使用两种新的数据扩增方法:边角crop和scale jittering。边角crop只从边角或者中心来选取图片区域,避免过多地集中于中心区域;在多尺度crop中,我们将ImageNet中使用的scale jittering技术用于动作识别,提出一个有效的scale jittering,将输入图片固定为256*340,crop的区域的宽度和高度,从{256; 224; 192; 168}中随机选择,最后将crop的区域resize成224*224,用于网络的训练,实际上,这种方法不仅包含scale jittering,还包括纵横比jittering。
用TSN进行动作识别
剪辑的视频中的动作识别
在剪辑的视频中,动作是人为地从长视频序列中crop出来的,因此动作识别可以简化为分类问题,由于所有snippet-level的卷积网络共享TSN中的模型参数,所以学到的模型能像一般的卷积网络那样进行frame-wise的预测,这也使得我们能与那些没有TSN网络的模型进行公平的比较。我们使用与原始的双流网络一样的测试方案,采样25个不同模式的snippet,同时,crop采样的snippet的4个边角和1个中心,以及中心flip来评估卷积网络,对于多个模式预测结果的融合,我们使用加权平均的策略,权重由实验确定。之前说到在softmax之前是使用segmental consensus函数,为了依照训练方式进行模型的测试,我们融合了25帧的预测分数和softmax之前不同的stream。
未剪辑的视频中的动作识别
未剪辑视频中的动作识别最大的问题是包含很大比例不相关的内容,因为我们的动作模型是在剪辑的视频中进行训练,重新利用剪辑视频的技术,也就是简单平均化视频中每个片段的分数,存在将模型在背景内容上无法预测的响应考虑在内的风险,所以很有必要设计一个特别的方案。首先,总结一下未剪辑视频的问题:位置问题,动作的clip可能会出现在视频片段中的任意时间;时长问题,动作所在的clip可能长可能短;背景问题,不相关内容可能多种多样,并且可能占整个视频时长很大的比例。
为了解决以上问题,提出了基于检测的方法,首先为了覆盖动作可能出现的任意时间,我们从输入视频中以固定采样频率(如1FPS)采样snippet,然后使用训练好的TSN网络预测这些snippet,之后,为了覆盖动作clip高度变化的时长,在frame分数上进行一系列的不同尺寸的temporal划窗,取一个窗口最高的分数对应的类别。为了缓解背景带来的问题,使用top-K策略,将相同长度的窗口进行集成,不同窗口尺寸的结果进行投票来得到整个视频最终的分类结果。
对于一个有M秒的视频,我们将得到M个snippet,即{T1, T2, …, TM},输入到TSN模型后,将为每个snippet得到一个类别分数F(Tm),然后从{1,2,4,8,16}选择尺寸l,构建temporal划窗,窗口会沿着视频整个时长进行滑动,stride=0.8*l,对于一个起始位置为第s秒的窗口,得到的一系列snippet是{Ts+1,…,Ts+l},这个窗口的的类别分数Fs,l可以按如下公式表示,以l为尺寸,我们可以得到Nl个窗口,其中Nl=M/0.8向下取整,然后使用top-K策略,从Nl个尺寸为l的窗口中来得到consensus,即Gl,这里top-K的K=max(15, Nl/4向下取整),这给了我们尺寸分别为l={1,2,4,8,16}的5组窗口类别分数,最终的分数是对这5个Gl取平均,我们将这种分类方法称为Multi-scale Temporal Window Integration,简称M-TWI。
实验
Pytorch版本代码解读:测试代码,以base_model=”BNInception”,modality=”RGBDiff”,new_length=5为例,首先构建TSN网络,prepare_base_model:从tf_model_zoo中import BNInception,并设置base_model.last_layer_name=’fc’,若输入为RGBDiff,input_mean=[104, 117, 128]*(1+5);之后prepare_tsn,读取base_model最后一层的in_feature,并使用setattr的方法将base_model.last_layer_name属性设置为Dropout层,定义new_fc = nn.Linear(in_feature, num_class),并且new_fc的weights~N(0,1),bias为常数0;之后construct_diff_model,找到base_model第一个卷积层conv1,设置新的new_kernel_size = kernel_size[:1] + (3 * 5,) + kernel_size[2:],并根据new_kernel_size的size定义新的weights,用新的weights作为conv2d的权重,用setattr将此conv2d定义到网络中,得到新的以RGBDiff为输入的网络。此Pytorch版本的代码只看到了单流(时序stream),并未看到双流。
setattr是torch.nn.Module类的一个方法,用来为输入的某个属性赋值,一般可以用来修改网络结构,以setattr(self.base_model, self.base_model.last_layer_name, nn.Dropout(p=self.dropout))为例,输入包含3个值,分别是基础网络,要赋值的属性名,要赋的值;getattr同样是torch.nn.Module类的一个方法,与为属性赋值方法setattr相比,getattr是获得属性值,一般可以用来获取网络结构相关的信息,以getattr(self.base_model, self.base_model.last_layer_name)为例,输入包含2个值,分别是基础网络和要获取值的属性名。
数据库
剪辑的视频数据库就是HMDB51和UCF-101,UCF-101的评估方法使用THUMOS13挑战赛的方法,使用三个split进行评估;HMDB51的评估方法使用三个split的平均精度。未剪辑的视频数据库采用THUMOS14和ActivityNet v1.2,THUMOS14有101种人类的动作,包括训练集,验证集,测试集和背景集,我们使用训练集(UCF101)和验证集(1010个视频)用于TSN网络的训练,使用测试集(1575个视频)进行测试。ActivityNet v1.2有100种人类的动作,包括4819个训练视频,2382个验证视频和2480个测试视频,使用标准的split进行TSN网络的训练和评估,两个数据库使用的评估标准都是mean average precision (mAP)。AP是P-R曲线的面积,而mAP是所有类别AP的均值。
实现细节
batch_size=128,SGD的momentum=0.9,使用在ImageNet预训练的模型初始化网络权重,设置一个较小的学习率,在UCF-101中,对于空间网络,学习率初始化为0.001,每1500个迭代下降为原来的1/10,整个训练有3500次迭代;对于时序网络,初始化学习率为0.005,每12000和18000次迭代后下降为原来的1/10,最大迭代次数设置为20000.为了加速训练,我们使用多GPU的date-parallel策略,使用改进版本的Caffe和OpenMPI。UCF-101整个训练过程,使用8块TITANX GPU,空间网络的训练约持续0.6个小时;时序网络的训练约持续8个小时。其他数据库训练方法类似,只是更改下训练迭代次数。考虑到数据增广,我们使用位置jittering、水平flip、corner crop和scale jittering技术,对于光流的提取和warp,我们使用基于OpenCV和CUDA的TVL1算法。
方法的有效性
不同的训练策略
与原始的双流网络相比,我们提出了两种新的训练策略:交叉模式预训练和partial BN+Dropout。我们在UCF-101的split1上进行以下对比:从头训练;像双流网络一样只预训练空间流;交叉模式预训练;交叉模式预训练和partial BN+Dropout组合的方法。四种方法对比度的结果如下表所示,首先,从头训练的方法远不如原始的双流网络,说明仔细设计的学习策略对于减少过拟合风险是很必要的,尤其对于空间网络;第2、3中方法是好于baseline,而最后一种方法的效果是最好的,所以在后面的实验中,我们都使用这种性能好的方法用于模型的训练。
不同的输入模式
本文提出两种输入模式:RGB差异和warped optical flow fields。我们尝试组合不同的模式并将结果展示在下表中,这些实验都是在上表中表现最好的方法的基础上进行的,我们还进行了包含/不包含TSN的几个实验来评估不同输入模式的性能,我们可以看到,RGB+光流的这个组合,作为双流网络的基础组合,在包含TSN时依旧性能很好,之后加上warped optical flow field稍微提升了性能,但是降低了速度,所以只使用RGB+光流来报告最终的性能。另外,当RGB差异+RGB+TSN组合时,可以取得很有竞争力的性能,同时速度很快——340FPS,这说明RGB+RGB差异的组合能提升识别精度,同时能达到实时。
TSN网络的实验研究
TSN网络有两个关键组成部分:稀疏snippet采样策略和segment consensus (集成)函数,为了更深地分析TSN网络,我们评估这两个组成部分的性能。数据库使用的是UCF-101和ActivityNet,使用RGB图片和光流场作为输入模式,为了证明TSN在长时建模的重要性,也比较了另外两种深度网络的TSN结构在UCF-101上的表现。
segment数量的评估
控制稀疏segment采样策略最关键的参数是segment的数量K,当K=1时,TSN就变成了原始的双流网络,增大K有望能提升识别性能。在实验中,我们更改K的数量,从1到9,识别结果如下表所示,我们观察到增大segment的数量会得到更好的效果,如7个segment的TSN会优于3个segment,这个提升说明使用更多的时序segment会帮助获取更丰富的信息来更好地建模整个视频的时序结构。但是,当K从7增大到9后,性能饱和了,因此,考虑到识别性能和计算消耗的平衡,我们在下面的实验中设置K=7。
集成函数的评估
segment consensus函数是由集成函数G定义的,对于最终的识别性能很重要,这里我们评估了五种策略:max-pooling, average-pooling, 加权平均、top-K pooling和attention权重,对比结果如下表所示,在UCF-101中,average-pooling集成函数性能最佳,在ActivityNet中,top-K和attention权重取得了相当的结果,这说明越复杂和不同的时序结构,高级的集成函数越能得到更好的识别精度,所以,对于短视频我们默认使用average-pooling,对于复杂视频,默认使用top-K pooling。
CNN结构的对比
以上实验多是在BN-Inception结构上进行,这里我们比较不同网路结构在UCF-101上的性能,结果如下表所示,在这些实验中K=1,即相当于原始的双流网络,我们比较了4种深度网络的性能:BN-Inception, GoogLeNet, VGGNet-16和ResNet-152。在比较的这些网络中,从BN-Inception中改编的深度双流网络取得了最好的效果,依旧优于ResNet-152,这可能是因为本文提出的方法,另外,当使用TSN (K=7)进行训练时,精度又有了提升,这很明显证明了使用TSN建模长时时序结构的有效性。
与state-of-the-art进行对比
在分析了TSN网络中的组成部分并得到合理的设置后,开始于其他方法进行对比,在实验中我们使用RGB和光流模式,来与之前的方法进行公平的对比。
除了在四个剪辑和未剪辑视频数据库上进行试验,还在ActivityNet挑战赛中得到了验证,在挑战赛中我们使用ActivityNet v1.3的视频进行训练和测试,考虑到CNN的结构对于提升性能中起到关键作用,我们也用Inception V3和ResNet来初始化网络。
为了评估TSN的性能,提出在v1.3的训练子集上训练模型,在验证子集上测试识别精度mAP;在训练和验证子集上训练TSN,在测试子集上测试精度,测试子集的mAP是通过挑战赛公开的测试服务得到的,验证集的结果如下表所示,我们发现TSN极大地提高了双流网络的性能,通过使用深度CNN结果如Inception V3,性能得到了进一步提升,而且,高级集成函数,如Top-K pooilng得到了更好的结果。
测试集上的结果如下表所示,这次的提交是TSN在训练和验证集上进行训练、使用Inception V3和ResNet-152结构、在视频的语音信号中训练语音模型的组合结果,得益于TSN的高效率,我们的模型可以使用一个单节点8 TitanX GPU上训练10小时得到。
模型可视化
我们使用DeepDraw工具来进行可视化,该工具对只有白噪声的输入图像进行迭代梯度上升,因此经过多次迭代后的输出可以看成是基于卷积模型中的类别知识的类别可视化,这个工具的原始版本只支持RGB,为了支持基于光流的方法,我们调整了工具,所以我们第一次可视化动作识别卷积模型中的类别信息。我们从UCF-101中随机选择5类,从ActivityNet中随机选择5类,结果如下图所示,对于RGB和光流,我们通过两种设定来可视化卷积网络:没有TSN的训练和有TSN的训练。另外,只用短时信息,如单帧,进行训练可能会误判场景模式和将视频中的目标误认为是动作识别中的关键目标,如在类别diving中,单帧的空间卷积网络可能看见水和diving平台,而不是看见diving的人;时序流部分,基于光流工作,趋向于关注由水花导致的运动。对于TSN的长时时序模型,很明显学习到的模型更关注于视频中的人,看起来是在建模动作类别的长时结构。依旧考虑diving,带有TSN的空间卷积网络生成一张人是最主要的视觉信息的图,图像中可以识别出不同的姿势,描绘出一个跳水动作的不同阶段,类似的观测也能在其他动作类别,如long jump和skate board中识别到,这说明带有TSN的模型性能会更好。