最近的动作识别方法多是基于CNN结构来提出不同的解决方案,本文探索了几种融合卷积网络的方法,得到以下结论:在卷积层上进行时空融合,而非softmax层,既不会降低性能,还能减少参数;在最后卷积层进行(spatially)融合网络比在之前的网络中融合的效果好,在类别预测层上的融合可以提高精度;沿周边的时空特征池化抽象的卷积特征能进一步提升性能。基于以上结论,本文提出了一个新的时空特征融合的CNN网络,代码是基于MATLAB来写的,还包括UCF-101和HMDB51的三个split和光流,以及VGG和ResNet在UCF-101上的预训练模型。
相关工作
本文指出,实际上在UCF-101和HMDB51上,目前最好的方法是卷积网络与基于轨迹手动提取特征的Fisher Vector (FV) encoding方法。可能因为目前用于训练的数据库规模还比较小,或包含的噪声较多;另一个原因是当前的卷积网络不能完全使用temporal information的优势,它们的性能常常被spatial(外观)识别所主导,在识别动作时大多是依靠spatial特征来进行识别。
像之前Early Fuson、Late Fusion的方法,对时间并不是很敏感,只是通过纯粹的spatial网络达到了类似的效果,这表明并没有从时间信息中获得更多;C3D模型比前一个方法深得多,结构类似于之前一个非常深的网络;将3D卷积分解成2D空间卷积+1D时间卷积的方法,它的时间卷积是一个随时间和特征通道而来的2D卷积,而且只在网络更高的层上进行。
而与本文最接近的,也是本文基于进行扩展的方法,是双流网络,该方法是将深度学习应用于动作识别,特别是在有限的数据集的情况下,最有效的方法;另一个相关的方法是双线性方法,Bilinear CNN models for fine-grained visual recognition (ICCV 2015),通过在图像每个位置的外积来关联两个卷积层的输出,在所有位置池化产生的双线性特征,形成一个无序的描述子。
在数据集方面,Sports-1M数据库是自动收集的视频,可能包含标签噪声;另一个大型数据库是THUMOS,有超过4500万帧,但只有一小部分包含对监督学习有用的labelled action。由于以上标签噪声,学习时空特征的卷积网络依旧很大程度上依赖于更小的,但是时序一致的数据库,如UCF-101或者HMDB-51,这有助于学习,也有可能产生严重的过拟合。
网络结构
之前的双流网络有两个不足:首先,由于只在分类层进行融合,所以无法学习时空特征之间pixel-wise的对应关系,其次,时间规模有限,空间卷积只在单帧上操作,时序卷积只在堆叠的L (L=10)个时序相邻的光流帧上,双流网络通过在规则的空间采样上使用pooling,在一定程度上解决了后一个问题,但并没有对行为的时间演变进行建模。
空间融合
这部分的目的是(在一个特定的卷积层)融合两个网络,使得相同pixel位置的通道响应能对应,以区分刷牙和梳头为例,如果人的手在周期性地在某个空间位置移动,那么时间网络就能识别到这个动作,空间网络能识别到位置(牙齿或者头发),两个网络的融合就能区分动作。
当两个网络在要融合的层有相同的分辨率时,通过一个网络与另一个网络的重叠(叠加)层,很容易获得空间响应,但同样存在一个问题,这个网络的通道对应另一个网络的哪个通道。假定空间网络中不同的通道负责不同的脸部区域(如嘴、头发等),时间网络中一个通道负责这个类型的周期性的运动场,那么经过通道的堆叠后,后面层的滤波器必须学习这些合适的通道间的对应关系,以便更好地区分这些动作。
具体来说,假定融合函数f能融合两个在时刻t的feature map,xat, xbt->yt,xat的shape=H*W*D,xbt的shape=H’*W’*D’,yt的shape=H’’*W’’*D’’,在包含卷积、全连接、池化和非线性层的卷积网络中,f可以用于网络中不同的层来实现Early-Fusion, Late-Fusion和多层融合,可以使用多种融合函数f,为了简便,假定H=H’=H’’, W=W’=W’’,D=D’,并去掉下标t。
Sum-Fusion
ysum=fsum(xa, xb)计算了两个相同空间位置i, j, d的feature map的和: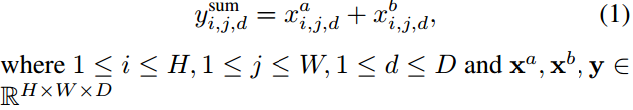
Max-Fusion
ymax=fmax(xa, xb)简单地取两个feature map的最大值,定义方法与Sum-Fusion类似。
Concatenation-Fusion
ycat=fcat(xa, xb)沿通道d,在相同的空间位置i,j堆叠两个feature map。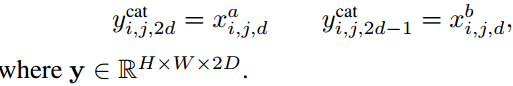
Conv-Fusion
yconv=fconv(xa, xb)首先按Concatenation-Fusion的方式堆叠两个feature map,然后对堆叠后的数据进行卷积,卷积核为f (shape=1*1*2D*D)。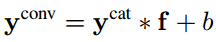
输出通道数量是D,这里的卷积核f是用来减少维度,并且能以权重的方式建模相同空间位置的两个feature map,当作为可训练的卷积核时,f能学到两个feature map之间的对应关系,以此来减少loss。
Bilinear-Fusion
ybil=fbil(xa, xb)计算每个特征图在每个像素位置的外积,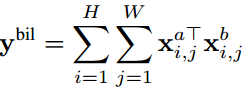
由此得到的特征获取了对应空间位置乘法的交互,这个特征主要不足是维度较高(ybil的shape=D2),为了使其在实际中可用,通常使用RELU5,移除全连接层,使用L2正则化,基于线性SVM进行分类。Bilinear-Fusion的优势是网络的每个通道都与其他网络的每个通道相结合(作为积),缺点是空间信息在这个点被边缘化了。
融合层的注入会对双流网络的参数和层产生重要影响,尤其是只保留了被融合的层,而其他层被截断,如下图左侧所示,
所以,可以在任意两个有相同空间维度的feature map上进行融合,即H=H’, W=W’。此外,也可以在两个层进行融合,如上图右侧所示,
时间融合
时间融合,即沿时间t组合特征图xt,得到结果yt,一种处理时序输入的方法是沿时间平均化网络的预测,这种情况只对2D(x, y)进行pool,如下图a中所示。考虑一个时序pooling层的输入为x, shape=H*W*T*D,通过沿时间t=1…T来堆叠空间的特征图生成。
3D-Pooling
使用尺寸为W’*H’*T’的3D pooling块对堆叠的数据进行max-pooling,这是将2D pooling延伸到时间域的最直接的扩展方法,如上图b所示,例如要pool三个时序样本,那么可以沿三个堆叠的对应通道进行3*3*3的max-pooling,没有不同通道间的pooling。
3D Conv+Pooling
首先对四通道的输入x进行卷积,滤波器尺寸为W’’*H’’*D*D’,卷积之后是上述的3D poolinig层,此方法如上图c所示,滤波器能以权重的形式,使用W’’*H’’*D的卷积核建模一个局部时空区域的特征的组合,这个区域通常是3*3*3(空间*时间)。
提出的网络结构
本文提出的网络结构可以看成是对空间融合方法左侧图沿时间维度的扩展,我们在最后一个卷积层,ReLU之后将两个网络融合进空间流,通过使用3D卷积和pooling将其转化为时空流,如下图左侧所示,此外,我们不截断时间流,并且在时间网络中使用3D pooling,如下图右侧所示,两个流的loss都用于训练,测试阶段我们将两个流的预测值进行平均,在实验中我们证实保持两个流的结构比在融合之后阶段时间流的效果好。
时间融合层的输入为T个时序块,间隔t’帧,也就是说,两个流的输入视频是t,t+t’,…t+Tt’,这使得我们能捕捉短尺度(t+L/2或t-L/2)的时序特征,如上图中一个箭头所示,并在更高层的长时域尺度中将他们放置在上下文中。因为光流对应的流的时域感受野是L=10帧,所以整个结构的操作时序感受野是T*L,注意t’<L导致时序流的输入有重叠,反之生成的是完全没有重叠的特征。
在融合之后,我们对间隔为t’帧的T个空间feature map进行3D pooling,由于特征可能会随时间改变他们的空间位置,组合空间和时间pooling成3D pooling是有道理的。例如,VGG-5在conv5的输出的输入stride是16个像素,从139*139的感受野中获取高级特征,对conv5进行间隔t’帧的时空pooling能获取相同目标的特征,即使他们有轻微的移动。
实现细节
双流网络
我们应用两个预训练的ImageNet模型,首先,为了便于与原始双流网络进行比较,使用VGG-M-2048模型,包括5个卷积和3个全连接;很深的VGG-16模型,包括13个卷积和3个全连接。我们首先分开训练原始双流网络的两个流,但有轻微不同:我们不使用RGB jittering;不使用以固定时间降低学习率的方法,而是在验证集的loss饱和后进行降低学习率;空间网络前两个全连接层的训练使用更低的dropout比例0.85,即使更低的比例0.5都没有严重降低性能。对于时序网络,使用光流作为输入,堆叠L=10帧,同样用在ImageNet预训练的模型作为初始化,输入最小的尺寸是256,训练之前先计算光流,并将光流存储为光JPEG图片,不使用BN层。
双流卷积Fusion
对于融合,使用batch_size=96进行finetune这些网络,当验证集的loss饱和时学习率降为原来的十分之一,反向传播时只传播到注入的融合层,因为整个网络的反向传播并没有提升性能。在实验中我们只融合相同分辨率的层,除了融合VGG-16中的ReLU5_3和VGG-M中的ReLU5,这次融合中我们对小的输入进行padding,即对VGG-M的输出(13*13,相比于14*14),添加一行0和一列0,对于卷积Fusion,我们发现注入融合层的初始化是很重要的,我们在实验中比较了多种方法。
最终整体架构中,3D卷积Fusion的滤波器f的维度是3*3*3*1024*512,T=5,也就是说时空卷积核维度W’’*H’’*T’’=3*3*3,D=1024,因为从时间和空间流中concatenate了ReLU5,D’=512匹配的是后面FC6的输入通道。还可以通过堆叠两个单位矩阵来初始化3D卷积核,来将1024个特征通道映射为512个,由于最后一个卷积层上的时间卷积网络的激活大约比其外观对应层的激活低3倍,因此我们将f的时间单位矩阵初始化高3倍。 f的时空部分是使用大小为3×3×3且σ= 1的高斯初始化的。此外,我们在训练期间不会在预测层上融合,因为这会使损失偏向于时间架构,因为时空架构 需要更长的时间来适应融合的特征。
训练3D卷积网络相比于双流卷积融合更容易过拟合,并且需要额外的增广方法,在finetune期间,在每个训练的迭代中,每个batch我们从96个视频中均采样T=5帧,从[1, 10]中随机采样初始帧随机采样时间跨度t’,所以是对总共15到50帧进行操作。不使用crop成固定的224*224的输入块,而是以正负25%的比例随机jitter宽度和高度并rescale成224*224。rescale是随机选择的,可能会影响纵横比,仅在距图像边界最大25%的距离(相对于宽度和高度)上进行块的crop,而且crop的位置,包括size,scale和水平flipping都是在第一帧中随机选择的,然后应用到堆叠的所有帧中。
测试
若没有特别说明,相比于原始双流网络中的25帧,这里只采样T=5帧,来进行更快地验证。此外我们进行了全卷积测试,使用整个帧,而不是空间的crop。
实验
实验评估用到的数据库是UCF-101和HMDB51,使用这两个数据库提供的验证protocol,并且报告训练和测试数据中三个split的平均精度。
原始的双流网络依旧使用两个VGG-M-2048网络,在最后一个卷积层的ReLu层后进行融合,融合的输入是两个流经过ReLU5之后的feature map,这样选择的理由是在之前的实验中,这种融合方法的效果最好,比其他融合方法如融合conv5的输出的效果好,融合层之后使用单个的处理流。在下表中比较了不同融合策略的效果,使用的数据是UCF-101第一个split。首先,这里的softmax平均性能(85.94%)与原双流网络中报道的性能相比具有优势;其次,Max和Concatenation稍逊于Sum和Conv融合,Conv-Fusion表现最好,稍好于Biilnear和简单的通过求和方式的融合。对于表中所有的融合方法,在FC层的融合性能稍逊于ReLu5,我们认为ReLu5这一层外观和运动之间的空间对应关系可能被融合了,而在FC层已经被破坏了。
在下面的表格中对比了融合不同层的性能,有趣的是,在ReLu5融合和截断一个网络得到了类似的分类精度,但前者的参数更少。
考虑到计算复杂度,之前的实验都是在两个VGG-M-2048网络上进行,如果使用更深的网络,性能会更好。这里使用了VGG-16网络,数据使用UCF-101和HMDB51,所有的模型都在ImageNet上进行预训练,并分别在目标数据库上进行训练,除了时序的HMDB51网络是使用时序UCF-101的模型进行初始化。下表是深层与更深层网络的效果对比,在这两个数据库中,更深的空间网络都有了很大的提升,而更深的时序网络精度提升较少。
下表展示了不同时序融合策略的效果,在第一行我们看到Conv-Fusion的效果比平均化softmax的输出效果好,接着发现在融合层后使用3D pooling比2D的效果好,两个数据库都是这样,在HMDB51的提升更多一些,最后在下表的最后一行展示了使用3D滤波器进行融合,更提升了精度。
接下来将本文提出的结构与state-of-the-art的方法进行对比,使用的数据是UCF-101和HMDB51所有的三个split,对比结果如下表所示,我们使用的方法是3D Conv和3D Pooling的融合方法。测试时,我们平均化来自每个网络的20个时序预测,输入来自密集采样输入的视频帧和他们的水平flip。一个有趣的比较是与原始双流方法的对比,使用VGG-16作为空间网络(S),VGG-M作为时序网络(T),在两个数据库上得到了3%的提升;都使用VGG-16时,在UCF-101上得到了4.5%的提升,在HMDB51上得到了6%的提升。
最后,我们探索了一种手工FV encodinig的IDT特征与我们的representation的late-fusion,在这里我们发现将卷积网络的预测与IDT特征组合,效果依然有提升,我们猜测如果有更多的训练数据,这种差异可能会随着时间消失,否则它表明未来的研究应该在哪里。