本文通过对人身体关节的跟踪集成了运动和外观信息,提出了P-CNN (Pose-based Convolutional Neural Network)描述子。在以往的动作识别方法中,基于局部运动描述子的方法在识别移动相机中的粗糙的动作中很成功,如站起来、挥手和跳舞等,基于全局特征的方法,由于缺少结构,不太适合识别微小的变化。
总体来说,这篇文章在以前几个方法的基础上做了集成和部分修改,在动作识别的任务中有一定成效。
PCNN网络结构
为了构建P-CNN特征,我们首先计算相邻帧的光流,计算方法借鉴ECCV-2004的论文:High accuracy optical flow estimation based on a theory for warping,速度较快,精度较高,在其他基于光流的CNN方法中都有应用,如双流方法,运动场vx和vy的值转换到[0, 255],转换的方法为a*vx|y+b,其中a=16,b=128。低于0的值和高于255的值都被截断,并将光流值转换为光流图,三个通道分别是转换后的vx和vy和光流幅值。
给定视频帧和对应的身体关节位置,我们将RGB图片patch和光流patch均crop成右手、左手、上身、整个身体和整张图片,每个patch均resize成224*224作为CNN的输入,为了表示外观和运动patch,我们使用两个独立的CNN网络,包括5个卷积层和3个全连接层,第二个全连接层的神经元个数是4096,作为视频帧的描述子fpt,对于RGB的patch,我们使用VGG-f网络,在ImageNet ILSVRC-2012上预训练;对于光流patch,我们使用CVPR-2015中Finding action tubes的网络,在UCF-101上进行预训练。
将所有帧的描述子fpt进行集成得到一个固定长度的视频描述子,集成的方法为求最小和最大。那么静态视频描述子可以表示为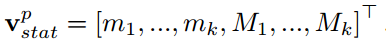
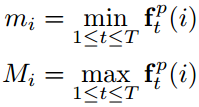
为了获取每帧描述子随时间的变化,考虑使用描述子之间的差值,同样计算差值的最大值和最小值作为动态视频描述子。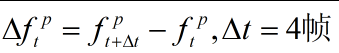
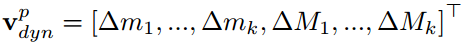
最终,将所有部位运动和外观特征归一化并拼接,归一化方法是除以训练集中fpt的平均L2范数。当然在后面的实验中也评估了不同集成方法的效果。
位姿估计
首先基于Mixing body-part sequences for human pose estimation (CVPR 2014)的方法为单独的视频帧预测位姿,此方法是基于可变性部位模型来定位身体关节的位置,在本文中使用时又在FLIC数据库上重新训练。在预测出关节的位置后,使用动态规划将它们连接起来,同时,限制一个位姿序列中的关节的运动与关节位置提取的光流一致。提取的关节如下图所示,包括成功的和失败的案例。
获得位姿后,提取HLPF (High-Level Pose Features),可参考Towards understanding action recognition (ICCV 2013),给定位姿序列P,首先相对于人的身高,将关节的位置进行归一化,然后计算每个关节相对于头的偏移量,而且相对于头的偏移量,比相对于躯干的偏移量更稳定。静态特征是所有关节对之间的距离,连接关节对的向量的方向以及连接所有关节三联体的向量所跨越的内角。动态特征是从关节的轨迹中获取的,图关节对之间距离的差异,连接关节对的向量方向的差异,内角的差异等,还包括关节位置的变化,关节方向的变化。
综上,一个视频序列可以表示成量化特征的直方图,分类器使用SVM。
实验
实验部分使用了两个数据库:JHMDB (HMDB的一个子集,ICCV 2013那篇文章提取了关节点)和MPII Cooking Activities,实验结果如下所示。