3D卷积网络(这里指的是3D Convolutional Neural Networks for Human Action Recognition)虽然效果还不错,但是其参数量较多,而且训练数据的规模也没有现在这么大,所以网络参数不易优化,根据这个局限,本文提出将3D时间空间学习分解成2D卷积+1D时间学习,提出了一种空间时间分解卷积网络。(自从17年Google的DeepMind提出了kinetics-400,kinetics-600数据集以后,数据量不再是3D卷积网络的局限,人们设计了很多巧妙的3D卷积网络,很大地促进了3D卷积网络的发展。)
网络结构
一个3D的卷积核可以表示成K (shape=nx*ny*nt),一个视频块V (shape=mx*my*mt),之前的3D卷积可以表示成Fst=V*K。拆分后的3D卷积核可以表示成:
公式中的乘法为Kronecker product(克罗内克积),Kx,y为2D空间卷积核,kt为1D时间卷积核,那么3D卷积等同于以下两步: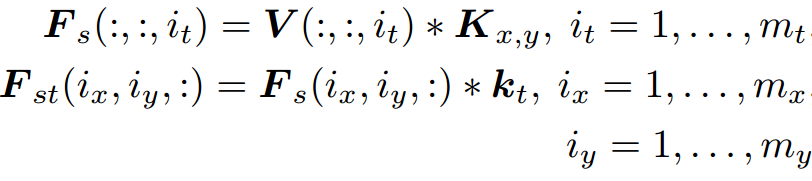
其中V(:, :, it)表示V中的一帧,Fs (shape=mx*my*mt)是对视频帧进行2D卷积的结果,卷积核为Kx,y,在卷积之前进行padding,Fs(ix, iy, :)表示Fs沿时间维度的向量,Fst (shape=mx*my*mt)是对Fs(ix,iy,:)进行1D卷积的结果,卷积核为kt,卷积之前进行padding。以上公式可以图示为:
从以上公式可以看出,可以通过学习一个2D空间卷积核和一个1D时间卷积核,并顺序使用学习的卷积核,来模拟3D卷积的过程,这样卷积核的复杂度从nxnynt变成了nxny+nt,而2D卷积核的学习可以利用现有的丰富的图片数据库。通常公式中3D卷积核的秩比一般的3D卷积核的秩低,我们通过分解方案来牺牲表达能力。但是,一般时空动作模式有低的秩,因为人动作的静态外观的特征表达在相邻的视频帧中有很大的相关性,如果他们不是低秩的,可以通过学习冗余的2D和1D卷积核并从中构造候选3D卷积核来弥补牺牲的表达能力。
本文提出的FSTCN结构如下图所示,首先,SCL(spatial convolutional layers)网络包含2D卷积、ReLU、LRN和max-pooling,每个卷积层必定包括卷积和ReLU,但不一定包括LRN和max-pooling。
为了提取运动特征,在SCL的顶端堆叠了TCL(temporal convolutional layer)层,与SCL结构类似,为了学习随时间演化的运动特征,在SCL和TCL之间插入了一个T-P算子层,如图中黄色区域所示。假定输入为4D的数组(水平x,竖直y,时间t,特征通道f)T-P算子首先沿水平和竖直维度向量化4D数组中的各个矩阵,每个尺寸为x*y的数组成为长度为x*y的向量,然后重新排列得到的3D数组(转换操作),以便可以沿着时间和特征维度学习和应用2D卷积(即TCL中的1D时间卷积,这里所谓的1D卷积实际上是沿着时间维度和特征维度的2D卷积)。简单来说,就是SCL的输出为C*T*H*W,首先沿高和宽展开,得到c*T*HW,然后调整一下维度顺序,变成HW*C*T,然后就可以在时间和特征维度上进行卷积。
数据增广
采样策略:本文训练和测试所使用的的样本是通过沿时间维度以某个stride,空间维度从相同位置进行crop得到的,这种采样方法不能保证采样的视频片段与动作周期对齐,但如果视频片段时间足够长,运动模式会很好地保留在视频片段中。
视频sequence V (shape=mx*my*mt),从中采样的视频片段Vclip (shape=lx*ly*lt),这种时间轴以某个stride为步长进行采样的方式,如果步长相对较大时,只能传递长时的运动,为了传递短时的运动,对于视频sequence V,我们同样计算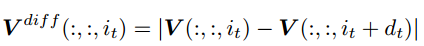
Vdiff既包括短时运动,也包含长时运动:Vdiff(shape=lx*ly*lt)包含短时运动信息,而Vdiff作为一个整体时包含整个视频的长时运动,跨度为(lt-1)st。
在实验中,采样了多个视频片段对{Vclip, Vclipdiff},并将视频片段对作为FSTCN的输入。这种采样策略类似于数据增广,将数据增广扩展到了时间领域,考虑到Vclipdiff包含了长时和短时的运动信息,而大部分的Vclip包含外观信息,那么采样对的使用方法如下:首先,将Vclip和Vclipdiff中单独的视频帧输入到低级SCL中,然后将从Vclipdiff中学到的特征经T-P算子后输入到TCL中,从Vclip中随机采样一帧输入到与TCL并列的中级SCL中。
训练与测试
为了高效学习时空卷积核,使用了辅助分类层,与低级的SCL相连,实际上,首先使用ImageNet预训练这个辅助网络,然后使用随机采样的视频帧来进行fine-tune,这里只fine-tune最后三层,最后整体训练FSTCN网络。有人用Pytorch复现了这个方法
测试时,给定一个测试动作序列,首先采样一对视频片段,然后将每个采样的视频对输入到FSTCN网络中,得到一个分类,然后将所有片段的分类结果融合得到最终的视频分类结果。
基于SCI的分类结果融合策略
假定动作识别数据库中有N种动作,我们从每个视频序列中采样M对{Vclip, Vclipdiff},每对视频片段正常crop,生成C个crop的结果,对于一个测试视频序列,第i个采样片段对的第k个crop视频表示为pk,i,其中k的范围为[1, C],i的范围为[1, M],最终的分类可以用简单的平均法来得到,即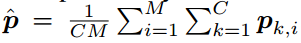
但这种方法不一样经常正确,实际上,如果一个人知道那个输出的分数更可靠,那么可以用带权重的平均法来得到一个更好的最终的分类。为了评估任意一个分数的可靠性,提出了一个很直观的想法:如果p可靠,那么它应该是稀疏的,分布的熵会比较小,也就是说,向量p中只有一些项是大的值,意味着测试视频序列属于相应动作类别的概率较高,而p中的其他项很小或接近0。当p不可靠时,它的每一项(类别概率)往往会均匀地分布在所有动作类别上。所以,我们可以用稀疏度来表示融合策略中的权重,从而提出了SCI (Sparsity Concentration Index)来评估每个p的稀疏度。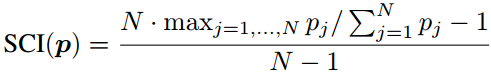
最终的类别分数可以表示为: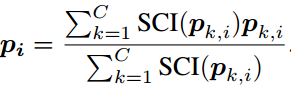
M对视频片段的结果可以融合为: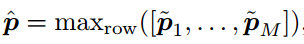
整个融合策略可以用如下图表示。给定测试序列,首先采样视频片段对,没对视频片段按左上,中上,右上,左中,中间,右中,左下,中下,右下进行crop,组成9个part,并经过flip得到18个样本,输入到FSTCN中,经过SCI策略得到18个分类分数,所有输出的分数取最大来得到最终的分类。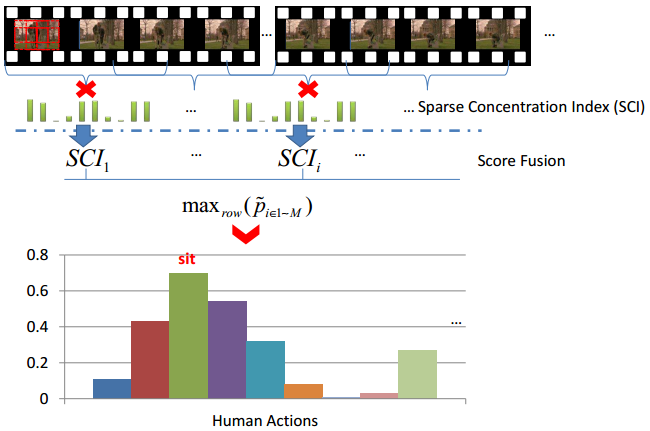
实现细节
前4个SCL,用于提取丰富和有判别性的外观特征,结构为Conv(96,7,2)-ReLU-Norm-Pooling(3,2)-Conv(256,5,2)-ReLU-Norm-Pooling(3,2)-Conv(512,3,1)-Conv(512,3,1),其中卷积表示为Conv(cf, ck, cs),卷积核数量为cf,卷积核尺寸为ck*ck,stride=cs,Pooling层表示为(pk, ps),与TCL相连的SCL包含卷积层(Conv(128,3,1)和Pooling(3,3))。转置矩阵P的尺寸为128*128,TCL有两个并列的卷积层(Conv(32,3,1)和Conv(32,5,1)),每个都有Dropout,比例为0.5,TCL没有接Pooling层因为会破坏时间线索,在TCL和SCL的顶端有两个全连接层,分别是4096和2048,batch_size=32,crop尺寸为204*204,没有使用一般的224*224,节省内存。
在复现的代码中,首先将clip和clip_diff沿axis=2合并,然后输入到SCL1-SCL2中,两个网络都是由Conv3d、ReLU和MaxPool3d组成,然后输入到SCL3-SCL4,结构为Conv3d+ReLU,然后从得到的特征向量中分离出clip和clip_diff对应的元素。对于clip部分,去掉维数为1的维度,输入到Parallel_spatial中,由Conv2d和MaxPool2d组成,然后reshape成向量,输入到spa_fc中,包括Linear、Dropout和Linear;clip_diff输入到Parallel_temporal中,包括Conv3d、MaxPool3d和TCL,TCL由branch1、branc2和cat组成,branch包括Conv3d、ReLu和MaxPool3d,最后沿axis=1合并,然后输入到tem_fc中,包括Linear、Dropout和Linear,最后将clip和clip_diff沿axis=1合并,并经过fc和softmax。
实验
在实验中,视频片段包含5个沿时间维度采样的视频片段对,dt=9,st=5,TCL路径为结构图中橘色箭头所示,并在HMDB51上测试在TCL中使用两种卷积核是否会比只用一种效果好,两种卷积核的尺寸分别是3*3和5*5,实验结果如下表所示,可以看出,使用两种不同卷积核的效果比只用其中一种的效果好,使用大的卷积核效果比小的好,这里的结果都是未使用SCI融合策略的结果,


可视化
为了可视化地证明FSTCN学习的参数的相关性,使用反向传播来可视化任意动作类别的重要区域,也就是将分类层中动作类别的神经元反传到输入图像领域,可视化结果如下图所示。图中显著图表示学到的参数能捕捉这个动作类别最有代表性的区域。
为了探究学到的时空特征对于动作识别是否具有判别性,将学到的特征画在了图中,动作类别包括HMDB-51中的smile、laugh、chew、talk、eat、smoke、drink。可视化方法为tSNE,因为这些动作主要涉及脸部运动,尤其是嘴部的移动,所以不太好区分。下图展示了SCL和TCL拼接后的FC层提取到的时空特征,比从SCL的第二个FC层提取到的时空特征,或者从TCL的第二个FC层提取到的空间特征,都具有判别性。