本篇论文是从ICML2010的基础上扩展的,提出了能从原始输入同时提取时间和空间特征的3DCNN,还提出了辅助特征的结构。
先说动作识别,动作识别可以应用在视频监控,顾客属性和购物行为分析,而之前的方法大部分采用两步走的策略:基于原始输入提取手工特征、基于特征学习分类器,而且对使用的环境做了假设(小的尺度变化和小的视觉变化),这样就存在一个问题,在实际的环境中,我们很难确定哪种特征对于识别动作是起关键作用的,因为特征的选择是取决于要解决的问题,尤其对于人的动作识别,不同的动作类别在外观和运动模式中会有很大的不同。
随着CNN在2D图像中表现的逐步提升,也想将CNN用于动作识别,而基于静态图片识别动作的方法并没有考虑到连续帧之间蕴藏的运动信息,所以本文提出了3DCNN结构,在输入的相同区域进行不同的卷积操作,能提取不同的特征。基于3D卷积操作,可以扩充成不同的3DCNN结构来分析视频数据。3DCNN结构能从连续帧中生成多通道信息,并且能在每个通道进行卷积核下采样操作,通过组合所有通道的信息得到最终的特征表示。
一、3DCNN网络结构
1、3D卷积
2D卷积是在空间维度上的卷积,那么3D卷积既是在空间上的卷积,也是在时间上的卷积。2D卷积的卷积核是二维的,3D卷积的卷积核是三维的,是个卷积块。2D和3D的区别如下图所示:
与2D卷积类似,一个卷积块只能从视频帧组成的块中提取一种特征。
2、3DCNN结构
基于以上提出的3D卷积结构,可以衍生出很多3D卷积的网络,这里提出一个用于动作识别的3D卷积网络,如下图所示:
在此结构中,输入为7个大小为60*40的视频帧,首先通过hardwire kernel,生成33个feature map,即每帧提取5个通道的信息:灰度、x方向的梯度、y方向的梯度、x方向的光流、y方向的光流(7+7+7+6+6),生成的feature map大小为60*40*33。hardwire层是使用了我们对特征的先验知识,比随机初始化性能好。可参考如下图: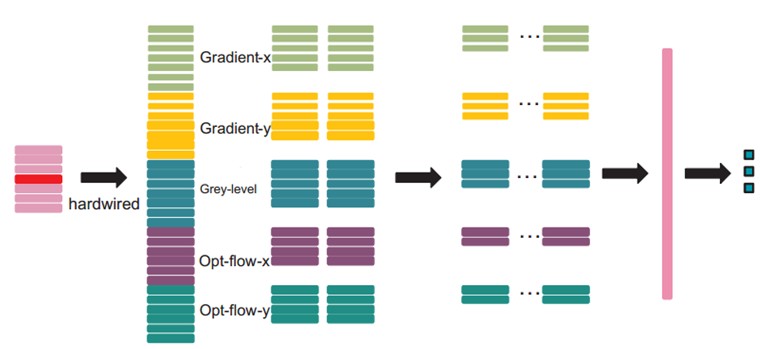
然后使用一个7*7*3的卷积核,分别在五个通道上进行卷积。为了增加feature map的数量,使用两组不同的卷积,得到两组不同的feature map (C2层),每组博涵23个feature map(5+5+5+4+4),大小为54*34*(23*2),在后来的降采样层S3,使用2*2的区域,得到的feature map大小为27*17*(23*2)。
C4层通过应用7*6*3的卷积核,在不同组的5个通道上单独进行卷积,这里使用3个卷积核,在C4层得到6个不同的区域,每个包含13个feature map (3+3+3+2+2),feature map大小为21*12*(13*6),下一层S5应用3*3的降采样,在这个阶段,时间维度的尺寸已经很小了,所以只在空间维度进行卷积,feature map大小为7*4*(13*6)。
C6层使用7*4的卷积核,输出的feature map大小为1*1*128,128个feature map与前面层所有的78个feature map相连。
经过所有的卷积和下采样层之后,原始输入的7个连续帧变成了一个包含运动信息的128维的特征向量,最终的输出层神经元个数就是动作的类别数量,激活函数使用线性激活函数。
由于随着输入窗口(卷积的时间维度)的增加,可训练参数的数量也增加,3DCNN网络的输入局限于很小数量的连续视频帧;另一方面,人的许多动作扩展在许多帧中,所以,需要将高级的运动信息编码在3DCNN模型中,为了达到这个目的,本文提出从大量的视频帧中计算运动特征并使用这些运动特征作为辅助输出来正则化3DCNN模型。对于每个训练的动作,除了通过CNN获取的输入视频帧组成的块的信息外,还生成一个编码长时动作信息的特征向量,然后使CNN学习一个接近于这个特征向量的特征(将辅助输出单元与CNN最后的隐层相连。在实验中,我们使用从密集SIFT描述子构建的词袋特征,在原始的灰度图像中计算得到,并以运动边缘历史图片(MEHI)作为辅助特征。加入辅助特征之后的网络结构如下图所示:
基于以上3D卷积结构,可以延伸出很多3DCNN结构,本文提出的网络结构是在TRECVID数据库上表现最好的,但是不一定适用于其他数据库。一种可用的方法是构造很多网络,以所有网络的输出来做最终的预测。
3、实验
数据库:TRECVID2018和KTH。
1)TRECVID2018
TRECVID2018数据库是在伦敦的Gatwick机场拍摄,使用5个不同的相机,以720*576的分辨率、25FPS的帧率拍摄共49小时的视频,由于4号相机的场景中发生的事件很少,所以排除了该相机。当前实验主要识别三种动作:CellToEar, ObjectPut, and Pointing,每种动作的分类方式是one-against-rest模式,即是该动作和不是该动作,负样本是除了这三种动作之外的动作,数据库共拍摄了5天:20071101, 20071106, 20071107, 20071108和20071112,每种动作使用的数量如下:
视频是在真实场景下拍摄的,所以一个场景包含多个人,使用行人检测器和检测驱动的跟踪器来定位人头,跟踪结果如下:
基于检测和跟踪的结果,可以给每个人计算一个发生动作的边界框,将边界框从跟踪结果中切割出来的结果如下图所示:
3DCNN网络需要的连续多帧就是通过在当前帧前后几帧的相同位置提取边界框来得到的,这样就能使一个立方块包含动作。在我们的实验中,立方块的时间维度设置为7,因为通过调研发现5-7帧的连续帧的表现已经足够与获取整个视频序列的表现相当,帧提取的step=2,也就是说,若当前帧是第0帧,纳闷我们在第-6、-4、-2、0、2、4、6帧中的相同位置提取边界框,每帧边界框中的图像块像素缩放成60*40。
用于对比的方案:2DCNN、基于局部特征的空间金字塔匹配(SPM),使用与3DCNN的输入相似的立方块,首先计算局部不变性特征,然后为每一类学习one-against-all线性SVM。对于密集特征,我们从原始的灰度图像(外观特征)或运动边缘历史图像(形状和运动特征)中提取SIFT描述子,SIFT特征是从7*7和16*16的局部图像块中的每6个像素来计算,
首先使用效果最好的3DCNN模型,标记为s332,其中s是指5个通道分开卷积;332是指前两个卷积是3D卷积,最后卷积使用2D卷积,此外,也测试了加了正则化之后的网络的效果。
使用五折交叉验证的方法,单独的一天作为一折,评估方法包括精度,召回率和AUC。效果最好的是3DCNN组合结果(1+2+3+4)。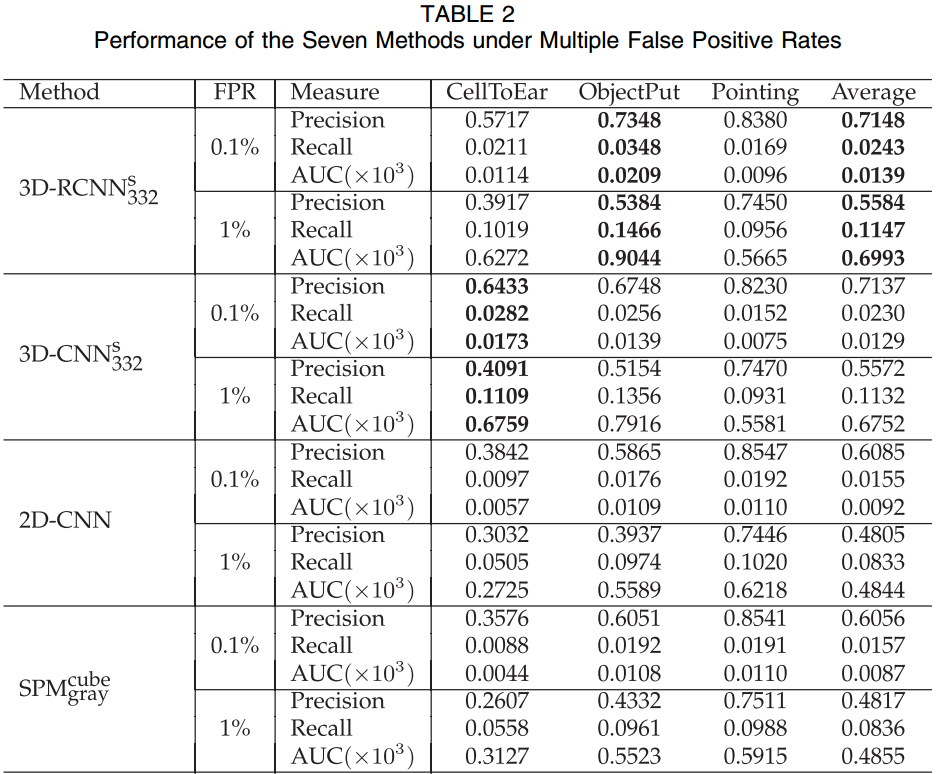






2)KTH
KTH数据库包括25个主体6中动作,以9帧为为一组输入,为了减少内存消耗,将输入缩放成80*60,三个卷积层的卷积核使用9*7, 7*7和6*4,两个降采样层使用3*3的卷积核,实验中,随机选择16个主体用于训练数据,其他的9个主体用于测试