由于当前动作识别数据库规模较小,使得大部分方法的性能都不相上下,在网络结构方面没有大的突破,本文在一个新的Kinetics Human Action Video数据库上重新评估了当前的方法,相比于之前的数据库,Kinetics增加了两个数量级的数据,有400个人类动作,每一类有至少400个视频片段,视频来源于YouTube;此外,本文还提出了一个新的双流Inflated 3D卷积网络——I3D,在2D卷积网络的基础上进行inflat,滤波器和pooling的核扩展为3D,并公开了Tensorflow版本代码,用到了deepmind自己的Sonnet。有其他人复现了1、2个Pytorch版本代码。
动作分类网络
现在的视频结构的差异主要在于,卷积层等层的操作是2D(基于图片)还是3D(基于视频);网络的输入是RGB视频还是也包括预先计算的光流;在2D卷积的网络中,信息是如何在帧之间传递的,可以使用LSTM或沿时间进行的特征集成。这里我们尝试了几种方案,如下图和下表所示。

第一个原始方法:卷积+LSTM
高性能的图像分类网络可以从视频帧中提取特征,然后沿整个视频对预测值进行pool,即可得到动作的预测,这种方法的灵感来源是词袋图像建模方法,但在实际中却忽略了时序结构,比如,模型可能无法区分开门和关门。所以,理论上一个更好的方法是添加一个recurrent层,比如LSTM,能编码状态,获取时序顺序和长时依赖。我们在Inception-V1的最后average-pooling层之后放置一个带有BN的LSTM层,隐层单元为512,在顶部添加一个全连接层用于分类。模型训练的loss是所有时间步的输出的交叉熵,测试时,只考虑最后一帧的输出,从原始的25帧/秒中,每5帧抽1帧作为输入样本。
第二个原始方法:3D卷积网络
相比于2D卷积,3D卷积由于卷积核维度更高,所以有更多的参数,这就使得3D卷积网络比较难训练;另外,由于无法使用ImageNet预训练,所以以前的方法都是定义比较浅的网络,并且从头开始训练。在动作识别中的效果不如现在的方法好。这种类型的方法是在我们更大的数据库进行评估的好的候选方法。
本文使用C3D的一个小的变种,有8个卷积层,5个pooling层和顶端的2个全连接层,输入是短的16帧的clip,从原始的数据中crop出112*112的区域。与C3D不同的是,我们在所有的卷积和全连接层后面使用BN层,而且第一个pooling层使用时序stride=2而不是1,能减少内存消耗,允许使用更大的batch进行训练,这对BN层很重要,尤其是在全连接之后。使用这种stride,我们能在K40的GPU上,每个GPU每个batch训练15个视频。
第三个原始方法:双流网络
卷积网络最后一层的特征进行LSTM能建模high-level的变化,但是可能无法获取low-level的运动,而low-level的运动在很多情况下是很重要的,而且训练的消耗也比较大,因为需要通过多个视频帧展开网络,以便在时间上进行反向传播。
这时就出现了一个很实际的、建模短时snapshot的方法,该方法将单个RGB视频帧和10个预先计算的光流帧输入到两个ImageNet预训练的卷积网络,并对预测值进行平均得到最终的预测结果。这种方法在现有的数据库上表现很好,而且训练和测试都很高效。最近对该方法进行的一个扩展方法,是在最后一个卷积层融合了时序和空间stream,在HMDB上有了一定提升,而且增加的测试时间更少。我们遵循这个方法,使用Inception-V1,输入为5个连续的RGB视频帧,间隔10帧采样,和对应的光流snippet。Inception-V1最后一个average-pooling之前的时空特征,也就是5*7*7,对应时间和x、y维度,输入到3*3*3的3D卷积中,输出通道为512,之后为3*3*3的3D max-pooling层,最后是全连接层。这些新的层的权重使用高斯噪声初始化。
新的方法:双流Inflated 3D卷积网络
将2D卷积扩展为3D,在原来2D卷积的基础上,增加时序维度,将原来N*N的正方形变成N*N*N的立方体。另外,如果想利用上ImageNet预训练模型的参数,我们可以将一个图片进行复制,从而转换成视频(boring video),那么,通过类似的方法,可以在ImageNet上预训练3D模型:在这种视频上pooled的激活值应该与原始的单张图片一样,而通过对2D滤波器的权重沿时间维度重复N次,即可使得卷积滤波器的响应是一样的。
事实上,所有的图片模型平等对待两个空间维度,也就是pooling的kernel和stride是一样的,这很自然,而且意味着网络中更深层次的特征在两个维度上都同样受到越来越远的图像位置的影响,然而,当同时考虑时间时,对称的感受野并不一定是最佳的,这取决于帧速率和图像维度。相对于空间,如果在时间上增长过快,可能会融合不同对象的边缘,破坏早期的特征检测,而如果增长过慢,则可能无法很好地捕捉场景动态。
在Inception-V1中,第一个卷积的的stride=2,之后是4个stride=2的max-pooling层和7*7的average-pooling层,最后是线性分类层,而且还有Parallel的Inception分支中的max-pooling层。在我们的实验中,输入视频的处理速度是25帧/秒,我们发现前两个max-pooling层不进行时序pooling是有帮助的(通过在时序维度使用1*3*3,stride=1),其他的max-pooling层使用对称的kernel和stride,最终的average-pooling层使用2*7*7的核,整个结构如下图所示,模型训练时使用64帧的snippet,测试时使用整个视频,沿时序维度平均预测值。
虽然3D卷积网络应该能直接从RGB输入中学习运动特征,但依旧是单纯的前向计算,而光流从某种程度来说是recurrent的(比如为光流场进行迭代的优化),或许缺少recurrence,实验中我们发现使用双流网络(e图)的设置是有价值的,I3D网络的输入为在RGB和另一个带有优化的光滑的光流信息的光流输入。我们分开训练这两个网络并在测试时平均化他们的预测。
实现细节
除最后一个用于生成分类分数的卷积层外,所有的网络卷积层后面接BN层和ReLU,3D卷积的训练需要更多的GPU来组成大的batch,这里使用64个GPU,在Kinetics上训练11w个step,validation loss饱和后,学习率降为原来的1/10。UCF-101和HMDB51使用16个GPU。数据增广使用随机crop,空间上将小的视频resize成256,然后实际crop一个224的区域;时间上,在足够早的时间内选择开始帧,以保证所需的帧数。对于短的视频,多次循环以满足每个模型的输入要求。我们还使用了为每个视频随机left-right的flipping。测试时,对整个视频进行224的中心crop,平均化预测值,也尝试了在256尺寸上的空间卷积,但是没有提升,未来可以尝试在测试时也进行left-right的flip。
Kinetic Human Action Video数据库
Kinetics数据库集中于人的动作,而不是活动或者事件,动作类别覆盖了人的动作(单个人),如drawing、drinking、laughing等;人与人之间的动作,如hugging、kissing、shaking hands;人与物品的动作,如opening presents、mowing lawn、washing dishes。有些动作是细粒度的,需要时间推理来区分,例如不同类型的swimming,其他动作需要更加关注物品来识别,如演奏不同种类的乐器。
数据库有400个动作类别,每个类别至少400个clip,每个clip都来自一个单独的视频,共24w个训练视频,每个clip持续约10s,没有未剪辑的视频;测试集每个类别包括100个clip。
实验
代码
代码中默认的模型是现在ImageNet,后在Kinetics上训练的模型,通过参数可以选择只在Kinetics上训练或者选择只用RGB stream或者光流stream,在checkpoint文件中包括5种checkpoint:flow_imagenet, flow_scratch, rgb_imagenet, rgb_scratch, rgb_scratch_kin600,若只是在Kinetics上训练,那么权重的初始化是使用默认的Sonnet/Tensorflow初始化方法;若权重是在ImageNet上预训练,那么权重是由2D的Inception-V1扩展为3D。RGB和光流stream是分开训练的,各自的loss都是softmax分类loss,有各自的学习率设置方法;测试时,将两个stream组合,以相同的权重添加logits。光流的提取方法:将RGB图像转换为灰度图,然后使用TV-L1算法计算光流,像素值范围截断为[-20,20],然后归一化到[-1,1]。RGB图像有3个通道,光流有2个通道。label_map和label_map_600是标签文件,分别包括400和600个动作类别。样例代码evaluate_sample.py中有rgb, flow, joint几种模式。3D卷积是用的sonnet.Conv3D(),定义为Unit3D(默认kernel_shape=(1, 1, 1), stride=(1, 1, 1), activation_fn=tf.nn.relu, use_batch_norm=True, use_bias=False),max-pooling是用的tf.nn.max_pool3d(),RGB网络结构为Conv3d_1a_7x7->MaxPool3d_2a_3x3->Conv3d_2b_1x1->Conv3d_2c_3x3->MaxPool3d_3a_3x3->Mixed_3b->Mixed_3c->MaxPool3d_4a_3x3->Mixed_4b->Mixed_4c->Mixed_4d->Mixed_4e->Mixed_4f->MaxPool3d_5a_2x2->Mixed_5b->Mixed_5c->Logits。用tf.variable_scope定义每个xx模块,若无特别说明,所有的Conv3D和pooling3d中的padding均为SAME。
Conv3d_1a_7x7: Unit3D(output_channels=64, kernel_shape=[7,7,7], stride=[2,2,2]),
MaxPool3d_2a_3x3: max_pool3d(ksize=[1, 1, 3, 3, 1], strides=[1, 1, 2, 2, 1]),
Conv3d_2b_1x1: Unit3D(64, kernel_shape=[1, 1, 1]),
Conv3d_2c_3x3 Unit3D(192, kernel_shape=[3, 3, 3]),
MaxPool3d_3a_3x3: max_pool3d(ksize=[1, 1, 3, 3, 1], strides=[1, 1, 2, 2, 1]),
Mixed_3b:各branch第一个网络的输入均为MaxPool3d_3a_3x3的输出,branch内部的“+”表示两个网络串联,第2个网络的输入为第1个网络的输出。用tf.variable_scope定义每个branch。
branch0: Unit3D(64, kernel_shape=[1, 1, 1])
branch1: Unit3D(96, kernel_shape=[1, 1, 1])+Unit3D(128, kernel_shape=[3, 3, 3])
branch2: Unit3D(16, kernel_shape=[1, 1, 1])+Unit3D(32, kernel_shape=[3, 3, 3])
branch3: max_pool3d([1, 3, 3, 3, 1], [1, 1, 1, 1, 1])+Unit3D(32, kernel_shape=[1, 1, 1])
concat([branch_0, branch_1, branch_2, branch_3], 4)
Mixed_3c:
branch0: Unit3D(128, kernel_shape=[1, 1, 1])
branch1: Unit3D(128, kernel_shape=[1, 1, 1])+Unit3D(192, kernel_shape=[3, 3, 3])
branch2: Unit3D(32, kernel_shape=[1, 1, 1])+Unit3D(96, kernel_shape=[3, 3, 3])
branch3: max_pool3d([1, 3, 3, 3, 1], [1, 1, 1, 1, 1])+Unit3D(64, kernel_shape=[1, 1, 1])
concat([branch_0, branch_1, branch_2, branch_3], 4)
MaxPool3d_4a_3x3:max_pool3d(ksize=[1, 3, 3, 3, 1], strides=[1, 2, 2, 2, 1])
Mixed_4b:
branch0: Unit3D(192, kernel_shape=[1, 1, 1])
branch1: Unit3D(96, kernel_shape=[1, 1, 1])+Unit3D(208, kernel_shape=[3, 3, 3])
branch2: Unit3D(16, kernel_shape=[1, 1, 1])+Unit3D(48, kernel_shape=[3, 3, 3])
branch3: max_pool3d([1, 3, 3, 3, 1], [1, 1, 1, 1, 1])+Unit3D(64, kernel_shape=[1, 1, 1])
concat([branch_0, branch_1, branch_2, branch_3], 4)
Mixed_4c:
branch0: Unit3D(160, kernel_shape=[1, 1, 1])
branch1: Unit3D(112, kernel_shape=[1, 1, 1])+Unit3D(224, kernel_shape=[3, 3, 3])
branch2: Unit3D(24, kernel_shape=[1, 1, 1])+Unit3D(64, kernel_shape=[3, 3, 3])
branch3: max_pool3d([1, 3, 3, 3, 1], [1, 1, 1, 1, 1])+Unit3D(64, kernel_shape=[1, 1, 1])
concat([branch_0, branch_1, branch_2, branch_3], 4)
Mixed_4d:
branch0: Unit3D(128, kernel_shape=[1, 1, 1])
branch1: Unit3D(128, kernel_shape=[1, 1, 1])+Unit3D(256, kernel_shape=[3, 3, 3])
branch2: Unit3D(24, kernel_shape=[1, 1, 1])+Unit3D(64, kernel_shape=[3, 3, 3])
branch3: max_pool3d([1, 3, 3, 3, 1], [1, 1, 1, 1, 1])+Unit3D(64, kernel_shape=[1, 1, 1])
concat([branch_0, branch_1, branch_2, branch_3], 4)
Mixed_4e:
branch0: Unit3D(112, kernel_shape=[1, 1, 1])
branch1: Unit3D(144, kernel_shape=[1, 1, 1])+Unit3D(288, kernel_shape=[3, 3, 3])
branch2: Unit3D(32, kernel_shape=[1, 1, 1])+Unit3D(64, kernel_shape=[3, 3, 3])
branch3: max_pool3d([1, 3, 3, 3, 1], [1, 1, 1, 1, 1])+Unit3D(64, kernel_shape=[1, 1, 1])
concat([branch_0, branch_1, branch_2, branch_3], 4)
Mixed_4f:
branch0: Unit3D(256, kernel_shape=[1, 1, 1])
branch1: Unit3D(160, kernel_shape=[1, 1, 1])+Unit3D(320, kernel_shape=[3, 3, 3])
branch2: Unit3D(32, kernel_shape=[1, 1, 1])+Unit3D(128, kernel_shape=[3, 3, 3])
branch3: max_pool3d([1, 3, 3, 3, 1], [1, 1, 1, 1, 1])+Unit3D(128, kernel_shape=[1, 1, 1])
concat([branch_0, branch_1, branch_2, branch_3], 4)
MaxPool3d_5a_2x2:max_pool3d(ksize=[1, 2, 2, 2, 1], strides=[1, 2, 2, 2, 1])
Mixed_5b:
branch0: Unit3D(256, kernel_shape=[1, 1, 1])
branch1: Unit3D(160, kernel_shape=[1, 1, 1])+Unit3D(320, kernel_shape=[3, 3, 3])
branch2: Unit3D(32, kernel_shape=[1, 1, 1])+Unit3D(128, kernel_shape=[3, 3, 3])
branch3: max_pool3d([1, 3, 3, 3, 1], [1, 1, 1, 1, 1])+Unit3D(128, kernel_shape=[1, 1, 1])
concat([branch_0, branch_1, branch_2, branch_3], 4)
Mixed_5c:
branch0: Unit3D(384, kernel_shape=[1, 1, 1])
branch1: Unit3D(192, kernel_shape=[1, 1, 1])+Unit3D(384, kernel_shape=[3, 3, 3])
branch2: Unit3D(48, kernel_shape=[1, 1, 1])+Unit3D(128, kernel_shape=[3, 3, 3])
branch3: max_pool3d([1, 3, 3, 3, 1], [1, 1, 1, 1, 1])+Unit3D(128, kernel_shape=[1, 1, 1])
concat([branch_0, branch_1, branch_2, branch_3], 4)
Logits:
tf.nn.avg_pool3d([1, 2, 7, 7, 1],[1, 1, 1, 1, 1], snt.VALID)+tf.nn.dropout()+Unit3D(num_class, kernel_shape=[1, 1, 1],activation_fn=None, use_batch_norm=False)+(tf.squeeze(axis=[2, 3]),指定此项为True/False)+reduce_mean(axis=1)
Prediction:tf.nn.softmax()。若为原来的Inception-V1,那么这个模块是存在的;若只是RGB或光流stream,那么到上一层Logits即可。
以上即为I3D的模型,模型搭建好后,使用variable.name.replace(‘:0’, ‘’)替换名称。如果eval_type=rgb或rgb600,则只将rgb_logits作为model_logits;若eval_type=flow,则只将flow_logits作为model_logits,若eval_type=joint,则model_logits=rgb_logits+flow_logits,然后将model_logits输入到softmax中。若需要载入预训练模型,则在rgb或光流stream中导入对应的权重文件即可。
实验结果

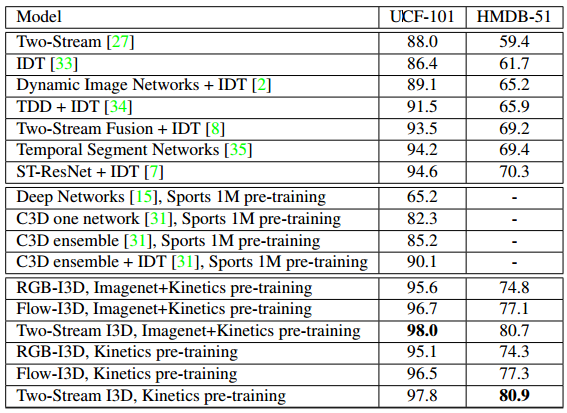
测试使用的是UCF-101和HMDB51的split1,以及Kinetics的held-out测试集,从结果来看,首先,新的I3D模型不是在所有的数据库中都是最好的,无论是使用RGB还是RGB+光流的模式;第二,所有模型在Kinetics上的表现远低于UCF-101,也说明了两个数据库难度的差异,但是比HMDB51的表现好,这可能是因为HMDB51缺少训练数据,或者这个数据库故意做的比较难:许多clip在相同的场景中有不同的动作,如“拔剑”的例子和“拔剑”和“练剑”是来自同一段视频。第三,不同结构的排序基本一致。另外,双流网络在所有数据库中表现都很好,但是RGB和光流的相对值在Kinetics和其他数据库中完全不同,在UCF-101中,单独的光流的贡献,稍微高于RGB,视觉上来看,Kinetics有更多的相机运动,会使运动stream变得困难。相比于其他结构,I3D从光流stream受益更多,可能因为有更长的时序感受野和更集成的时序特征。本文还评估了从ImageNet预训练和从头训练两种方法来训练Kinetics,结果如下所示,ImageNet预训练的方法在所有情况下都是有帮助的,尤其对于RGB stream。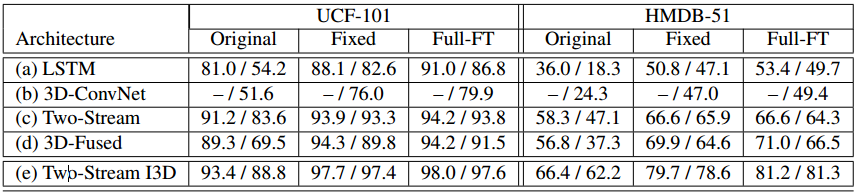
此外,考虑Kinetics训练的网络的通用性,首先,冻结网络权重,使用网络为UCF-101或HMDB51中没见过的视频生成特征,然后使用各个数据库的训练数据来训练softmax分类器,在测试集上评估;其次,使用数据库中的训练数据,为UCF-101或HMDB51 finetune每个网络,并在测试集上测试。还评估了再ImageNet+Kinetics,而不是仅仅的Kinetics上预训练的重要性。结果如下表所示。

所以,在大规模视频数据库,如Kinetics上进行预训练是有用的,但是使用Kinetics预训练的模型用于其他任务如视频语义分割、视频中的目标检测或者光流计算等任务,还有待验证。另外,我们没有进行全面的探索,比如没有使用action tubes或者attention机制来集中注意在人的动作中。空间和时间之间的关系很神秘,许多研究都试图获取这种关系,比如为动作类别学习frame ranking函数并使用这些作为表示;或者创建frame序列的2D视觉snapshot,这个想法与经典的运动历史有关,如果把这些模型都作为对比方案是更好的,但需要时间来验证。