现有的方法依赖光流特征,而传统的光流计算需要为CNN预先计算运动信息,这种两阶段方法计算量大,存储空间需求大,不是可端到端训练的。本文提出一种新的CNN结构用于提取运动信息,我们称之为hidden双流CNN,因为只需要原始像素作为输入,在不需要计算光流的情况下直接预测动作类别,速度10倍快与原始的双流网络,在UCF-101、HMDB51、THUMOS14和ActivityNet v1.2上都是最好的实时动作识别方法。
经过几年的发展,动作识别方法已经从原来的手动提取特征到现在的学习CNN特征;从encoding外观信息到encoding运动信息;从学习局部特征到学习全局特征。最初的CNN用于动作识别的效果并不是太好,甚至还不如iDT,可能是因为这时候的CNN比较难获取视频帧之间的运动信息,后来的双流网络通过使用传统光流预先计算光流特征解决了这个问题,时序stream极大地提升了CNN的精度,在几个数据库上都超过了iDT。但是现有的CNN网络依旧很难直接从视频中提取运动信息,而先计算光流,再把光流映射为动作标签是一个次优的方法:与CNN步骤相比,光流的预计算耗时耗空间;传统的光流评估完全独立于最终的任务,有研究(Video Enhancement with
Task-Oriented Flow, arxiv 2017)表明,固定的光流计算方法不如任务导向的光流计算方法的效果好,所以之前的光流计算方法是次优的。为了解决这个问题,出现了运动向量(20倍快于传统双流网络,但编码之后的运动向量缺少好的结构,并且包含噪声和不正确的运动模式,所以导致精度却下降很多,请见论文:Real-time Action Recognition with Enhanced Motion Vector CNNs, CVPR 2016)、RGB图像差异或者RNN、3DCNN等结构,但是大多数不如光流特征,在动作识别的任务中有效。
Hidden双流网络
无监督光流学习
我们将光流计算方法看成图像重建问题。给定一对视频帧,我们希望生成光流,允许我们从一帧重建另一帧。例如,给定输入I1和I2,CNN网络生成了光流场V,然后使用光球场V和I2,通过backward warping,我们能得到重建帧I1‘,且I1‘=T[I2,V],其中T是inverse warping函数,我们的目标是最小化I1和I1‘的photometric误差。如果使用计算的光流和下一帧能重建当前帧,说明网络已经能学习到当前运动的有效表示。
MotionNet
我们提出的MotionNet是一个全卷积网络,包括一个收缩部分和一个扩展部分,收缩部分是堆叠的卷积层,扩展部分是一系列组合的卷积和反卷积层。首先,我们设计能专注于小位移的网络,现实的数据,如YouTube视频,我们经常遇到前景运动(人的动作)比较小,而背景运动(相机移动)比较明显的情况,所以我们使用3*3的卷积来检测局部的、小的运动。而且,我们保留高频的图像细节用于后续的阶段,我们前两个卷积层不使用stride,在图像的降采样中使用带有stride的卷积,而不是pooling,因为pooling不利于密集的每个像素的预测任务。
Loss
我们的MotionNet在多个尺度计算多个loss,由于收缩和扩张部分之间的skip connection,中间的loss可以彼此正则化,并且指导前面的层快速收敛到最终的目标。一个标准的pixelwise的重建误差如下所示,其中Vx和Vy是计算得到的光流的水平和竖直分量,inverse warping函数是使用的STN网络,loss是使用的鲁邦的凸损失函数,Charbonnier惩罚函数p(x)=(x2+theta2)a,来减少outlier的影响,h和w表示图片I1和I2的高和宽。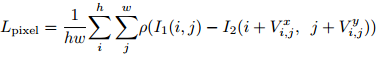
一个光滑的loss能解决aperture问题,避免出现非纹理区域的运动误计算,计算方法如下,前两个delta变量是光流场Vx在每个方向的梯度;后两个delta是Vy的梯度,p(x)同上。
结构相似度SSIM(Structural Similarity)损失函数能帮助我们学习帧的结构。SSIM是一个感知质量测度,给定两个K*K的图像patchIp1和Ip2,SSIM的计算方法如下,u和sigma分别是图像的均值和方差,sigmap1p2是协方差,c1和c2是为了避免出现除0,在实验中,K=8,c1=0.0001,c2=0.001
为了比较两张图片I1和I1‘的相似度,我们采用划窗法,将图片分成局部的patch,划窗的水平和竖直stride=8,损失这里的SSIM函数定义如下,N是patch的数量,n是patch的索引,I1n和I1n‘是patch实验证实,简单的策略能提升计算的光流的质量,使得MotionNet生成有清晰运动边界的光流场。
所以,每个尺度s的loss是以上几项的加权和,表示如下。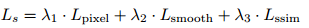
因为在decoder有5个扩展,所以我们有5个尺度(flow2到flow6)的预测,MotionNet的最终loss是Ls的加权和,表示如下。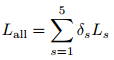
在学习光流的过程中,我们还在反卷积之间加入了卷积层,来得到更平滑的运动估计,我们也探索了其他方法,如添加光流置信度,并且在expand部分呈上原始带颜色的图像,但是,并没有发现有提升。在后面的实验中有证实。
将运动特征映射为动作
MotionNet和时序stream都是基于CNN来搭建的,我们想将这两个模型组合,并进行端到端的训练,有多种组合方法,这里我们探索两种:堆叠和branch法。堆叠法是最直接的组合方法,直接将MotionNet放在时序stream的前面;branch法是结构设计中更优雅的方法,使用单个网络同时实现运动特征提取和动作识别,两个任务共享卷积特征,但堆叠法是更有效的方法,能实现更准确的动作识别同时对空间stream是个互补,在后面的实验中,我们都是使用堆叠的方法将运动特征映射为动作类别。
在堆叠网络时,在输入encoding CNN之前,我们首先需要归一化计算的光流,说先将大于20个像素的运动clip为20个像素,然后归一化和量化clip之后的光流,使其范围为0~255,我们发现这种归一化方法对好的时序stream表现很重要,并且为它设计一个新的归一化层。其次,我们需要决定如何finetune网络,包括finetune时使用哪个loss,我们探索了不同的组合:(a)固定MotionNet,不适用action loss来finetune光流计算;(b)MotionNet和时序CNN一起finetune,但是只计算动作类别的损失函数,不包括无监督部分Ls;(c)MotionNet和时序stream都finetune,计算所有的损失函数。因为运动与动作强相关,我么希望通过这种多任务学习来学习更好的运动表示。在实验中,最后一个组合的效果最好。此外,我们需要计算长时运动依赖,我们通过输入一个堆叠的多个连续光流场来实现,有学者发现堆叠10个光流场比只用一个光流场的效果好,为了进行公平对比,我们也固定输入的长度为11帧,这样就能生成10个光流场。
Hidden双流网络
我们也会展示将空间stream与堆叠的时序stream组合的识别结果,这些结果能证明我们堆叠的时序stream实际上能学习到互补的运动信息还是只是外观信息。与之前方法的设置类似,我们在每个视频中均匀采样25帧/clip,对于每帧/clip,进行10倍的数据增广,方法为crop 4个角和1个中心,水平flip,并在softmax之前平均化所有的crop的预测值,最终融合两个stream的分数,比例为空间stream:时间stream=1:1.5。
实验
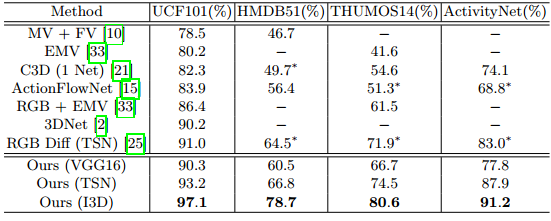
首先比较了一些两阶段的方法,其中光流是预先计算,缓存,然后输入到CNN分类器中来将光流映射为动作标签,为了公平比较,我们的MotionNet先在UCF-101上预训练,但没有使用动作类别损失函数finetune,只是将一对视频帧作为输入,输出一个计算的光流。在中间部分是端到端的基于CNN的方法,这些方法都没有存储中间的光流信息,所以速度快于两阶段方法,如果将这些方法的平均时间与两阶段方法相比,耗费在读和写中间结果上的时间几乎是其他步骤的3倍,因此,端到端的方法更高效。其中ActionFlowNet就是branch的时序stream,是一个多任务学习模型,同时计算光流特征和识别动作,贡献卷积特征能使速度更快,但是即使是16帧的模型依旧不如我们堆叠的时序stream的效果好,而且ActionFlowNet使用传统方法计算得到的光流作为标签来进行监督训练,这表示训练期间依旧需要缓存光流。单个空间stream的精度是80.97%,在最下面一部分是双流网络的结果,我们看到识别效果的提升是将堆叠的时序stream与空间stream合并得到的,这些结果表明我们堆叠的时序stream网络能直接从视频帧中学习运动信息,并且相比于单独的空间stream,能取得很好的成效,这说明我们的非监督预训练能为CNN找到一个更好的学习识别动作的途径,并且这个途径不会在finetune阶段被遗忘。另外,三种合并方法之间效果的差异,可能是因为没有非监督loss的正则化,网络开始学习外观信息,所以对于空间CNN来说,就不那么互补了。
讨论
这个部分跑了一个ablation study来证明不同损失函数或者操作的重要性。表格中Small Disp表示使用注重于小的位移的网络,CDC表示在MotionNet的扩展部分的反卷积之间添加额外的卷积,MultiScale表示从多个尺度计算loss。
此外,还探索了不同运动评估方法的效果,和他们计算光流场的质量,这里主要用到了三个光流模型,在四个benchmark上进行测试光流计算的质量,在UCF-101的split1上计算动作识别的精度,使用EPE (Endpoint Error)来评估MPI-Sintel, KITTI 2012和Middlebury,使用Fl (percentage of optical flow outliers)来评估KITTI 2015,都是越小越好,使用分类精度来评估UCF-101,值越大越好。
另外还对一些样本进行可视化来帮助理解计算的光流场的质量对于动作识别的效果,颜色是使用标准的光流场的颜色(FlowNet
2.0: Evolution of Optical Flow Estimation with Deep Networks, CVPR 2017),整体上看,三种方法计算的光流场都看起来很合理,相比于TV-L1,MotionNet有很多背景噪声,因为是全局学习,这也可能是它的表现不如TV-L1的原因。FlowNet2有很明显的运动边界、好的结构和平滑性,考虑到EPE和视觉观察,其实是一个很好的光流计算方法,但是用于动作识别的效果却不如另外两个方法,所以,运动表示对于动作识别是最好的方法依旧是一个开放性的问题。
未来有几个改进的方向,首先,基于smooth损失对于动作识别运动特征的评估有很大的影响,在后期计划提升光流预测的效果;借鉴其他提升网络效果的方法,如联合训练两个stream,而不是简单的late fusion;解决错误标签assignment问题是否会提升整体效果;在CNN网络中消除全局相机移动和局部部分遮挡对于光流的计算和动作识别有帮助。