本文是为解决大规模visual place recognition问题,快速准确识别一个查询照片的位置,也就是说,给定一张图片A,要从其他图片中找到一张图片,这张中带有图片A中的地点,如下图所示。本文主要有三个贡献点:提出一个端到端可训练的卷积网络,核心部分NetVLAD是一个新的VLAD层,VLAD (Vector of Locally Aggregated Descriptors)是一个常用在图片检索中的图片表示方法;其次,基于弱监督排行loss提出一个训练策略;最后,提出的方法性能很好。本文的代码已公开,是用MATLAB写的。
VLAD网络
VLAD算法可以看做是一种简化的FV,其主要方法是通过聚类方法训练一个小的codebook,对于每幅图像中的特征找到最近的codebook聚类中心,随后所有特征与聚类中心的差值做累加,得到一个k*d的vlad矩阵,其中k是聚类中心个数,d是特征维数(如sift是128维),随后将该矩阵扩展为一个(k*d)维的向量,并对其L2归一化,所得到的向量即为VLAD。
算法流程
(1) 读取图片文件路径及特征提取
(2) 使用聚类方法训练codebook
(3) 将每张图片的特征与最近的聚类中心进行累加
*(4) 对累加后的VLAD进行PCA降维并对其归一化
*(5) 得到VLAD后,使用ADC方法继续降低储存空间和提高搜索速度
其中步骤4、5可选,在步骤3得到残差累加向量后进行L2归一化即可用欧氏距离等计算两张图片的相似性从而实现图片检索。有部分实现VLAD的代码。
place recognition的深度网络
本文将place recognition看成图像检索问题来处理,带有未知地点的query图片用来可视化搜索大型地理标记图像数据库,top ranked的图片用来作为query的location的建议。通常要设计一个函数f作为图片表示提取器,给定图片Ii,生成一个固定尺寸的向量f(Ii),函数f可以离线计算整个数据库{Ii}的表示,在线提取query图片的表示f(q),在测试时,通过基于f(q)和f(Ii)的欧式距离d(q, Ii),查找与query最近的数据库图片来进行视觉搜索,或者近似最近邻查找。
大部分图片检索方法是基于提取局部描述子,然后以无序的方式pool描述子,这种方法对translation和partial occlusion有很强的鲁棒性。在本文提出的方法中,我们首先在最后的卷积层对CNN进行crop,并将其看成一个密集描述子提取器,那么若最后一个卷积层的输出为H*W*D,一系列在H*W区域提取的D维描述子,然后基于VLAD设计一个新的pooling层,将提取的描述子pool为一个固定长度的图片表示,而且这层的参数可以通过反向传播来学习,我们将这个新的层成为NetVLAD层。
NetVLAD:一个通用的VLAD层(fVLAD)
VLAD是一个常用的描述子pooling方法,常用于instance level检索和图片分类,能获取聚集在图像上的局部描述子的统计信息。bag-of-visual-words集成方法保留visual-words的计数,VLAD存储每个visual-words的残差(描述子与对应聚类中心的差异向量)的和,
给定N个D维的局部图像描述子{xi}作为输入,K个聚类中心(visual-words){ck}作为VLAD参数,输出的VLAD图像表示V是K*D维的,为了方便,将V写成K*D维的矩阵,但是这个矩阵是转换为向量,经过归一化之后,作为图像的表示,V中的元素(j,k)的计算方法如下所示,xi(j)和ck(j)分别是第j维的第i个描述子和第k个聚类中心,alphak(xi)表示xi与第k个visual-words之间的关系,如果聚类ck是最接近描述子xi的类,那么alpha=1,否则为0。V中每个D维的列k记录了分配给ck的、残差(xi-ck)的和,之后对矩阵V进行列方向的内部L2归一化,转化为向量,最后整体L2归一化。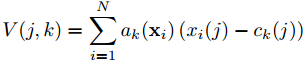
受益于图像检索其他方法,本文提出在CNN网络中模拟VLAD,设计一个可训练的通用VLAD层,即NetVLAD,结果是一个强大的可端到端训练的图像表示方法。但是网络中的层需要可微,而VLAD原本是不连续的,因为描述子xi到聚类中心ck的hard assignment值alphak(xi)。为了使这个操作可微,我们将其改为描述子到多个聚类的soft assignment,表示方法如下所示,让权重与描述子xi与聚类中心ck的接近程度成正比,但是与其他聚类中心的接近程度相关,新的alpha的值分布在0和1之间。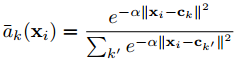
通过展开公式中的平方项,我们看到分子分母中的e-alpha||xi||2可以抵消,得到以下形式的soft assgnment。
其中wk=2*alpha*ck, bk=-alpha*||ck||2,那么NetVLAD层最终的形式如下所示。
其中{wk}, {bk}, {ck}是聚类k中的可训练参数,与原始VLAD描述子类似,NetVLAD层集成了残差xi-ck在描述子空间不同part的第一顺序的统计特征,权重为描述子xi到聚类k的soft-assignment,即新的alphak(xi)。但是与原始的VLAD参数{ck}相比,NetVLAD的参数有{wk}, {bk}, {ck},这能促进更好的平滑性,如下图所示。红色和绿色的圈是来自两个不同图片的局部描述子,分配给了相同的聚类,在VLAD的编码下,它们对两幅图像之间相似性得分的贡献是对应残差之间的标量积(因为最终的VLAD向量是L2归一化的),残差向量是描述子与聚类锚点之间的差异,锚点ck可以看成一个对于特定聚类k的新的坐标系统的原点,在标准的VLAD中,锚点是作为聚类中心(x)来使残差均匀地分布在数据库中,但是在一个监督学习中,我们知道两个描述子属于不匹配的图片,所以可能会学习一个更好的锚点(*),来使得新的残差的标量积更小。
如下图所示,NetVLAD层可以看做一个元层,这个元层进一步分解为连接在有向非循环图中的CNN层。首先,以上公式的第一项是一个softmax函数,所以,输入描述子矩阵xi到K个聚类的soft-assignment可以看成两个步骤的处理:有K个滤波器的1*1卷积{wk},{bk},生成输出sk(xi)=wkTxi+bk;然后将卷积输出输入到softmax函数sigmak来得到最终的soft-assignment,表示集成层不同项的权重,经过归一化之后的输出层是一个(K*D)*1的描述子。
当然,也有其他使用VLAD或者FV(Fisher Vecotrs)来pool卷积激活值的方法,但是并没有学习VLAD/FV的参数或者输入描述,与本文最相关的方法是一个学习FV参数,使用SVM作为最终分类器的方法,但是这个方法不能学习输入描述,因为是手动提取的SIFT特征,训练是使用的自下而上的贪心算法,而本文的VLAD层因为能反向传播,所以很容易插入到CNN网络中。
网络学习的方法
首先介绍来自Time Machine的弱监督学习,Google Street View Time Machine,一个提供不同时刻很多街道全景图片的数据库,对于place recognition中的图像表示是很有用的,这个数据库记录了街道在不同时间和季节的场景,为学习算法提供了一些关键信息,通过这些关键信息,学习算法可以发现哪些特征是有用的,以及图像表示应该对哪些变化具有不变性,从而来获得好的place recognition的性能。而数据库的不足在于,他提供了不完全和有噪声的监督。每一个Time Machine全景都有一个GPS标签,给定了它在地图上的大致位置,可用于识别附近的全景图,但不提供所描绘场景的各个部分之间的对应关系。由于测试的query是来自照相手机的透视图,因此每个全景图均由一组以不同方向和两个仰角均匀采样的透视图表示,每个透视图都标记了源全景图的GPS位置,两个地理上接近的透视图图像不一定描绘相同的对象,因为它们可能面对不同的方向或发生遮挡,如两个图片在一个corner附近。所以,给定一个测试query,GPS信息只能用作(i)潜在正值{piq},即地理上接近查询的图像,和(ii)确定负数{njp},即地理上距离查询远的图像的源。
其次,我们希望能学习一个能优化place recognition性能的表示ftheta,给定一个测试query图片q,目标是排序一个数据库图片Ii*,排序依据是位置近的高于其他地理位置远的图片,也就是希望query q与附近图片Ii*之间的欧氏距离dtheta(q, Ii*)小于dtheta(q, Ii)。从数据库中我们能得到一个tuple的训练数据库(q,{piq},{njq}),对于每个训练query图片q,我们有一组潜在的正值piq和确定的负值njq,签在的正值组包含至少一个正值图片与query匹配,但是我们不知道是哪一个,为了解决这个问题,我们提出为每个训练tuple(q,{piq},{njq})识别最匹配的签在正值图片pi*q,如下所示。
之后目标就变成了学习一个图片表示ftheta,使得训练query和最匹配的潜在正值之间的距离dtheta(q, Ii*)小于dtheta(q, njq),如下所示。
基于以上论述,我们定义一个弱监督排序loss,Ltheta,如下所示,l是hinge loss,l(x)=max(x, 0),m是一个常数,作为一个给定的margin,loss是对所有单个负值图片njq的求和,对于每个负值,如果query与负值之间的距离比query与最匹配的正值之间的距离大,且超过margin,则loss为0,否则正比于间隔。这个loss是与常用的triplet loss有关,但经过调整以适应这里的弱监督场景。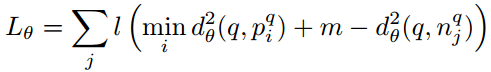
实验
实验中使用两种基础网络AlexNet和VGG-16,扩展方法为Max-pooling(fmax)和NetVLAD(fVLAD),都在最后的卷积层conv5,ReLU之前进行crop,对于NetVLAD,设置K=64。本文方法与其他方法的对比如下图所示,A代表AlexNet,V代表VGG-16。
放置在图像的同一位置时表示的变化,所有的热力图有相同的颜色尺度。但是原始图像和热力图没有完全对齐,因为附近的patch重叠50%,图像边缘的patch被丢弃,以防止边界效果。所有图片都未在训练集中出现过。")