本文介绍了一种新的用于动作识别的视频表示方法,通过将双流网络与科学系的时空特征组合,在视频的整个时空范围内聚合局部卷积特征,得到的结构是端到端可训练的,为整个视频分类。我们探索了沿空间和时间pooling的不同策略,以及几种组合不同stream信号的策略,我们发现联合pool空间和时间很重要,但是外观和运动stream最好汇总到各自单独的表示中。本文公布了TensorFlow版本的代码。
3D时空卷积方法能学习到复杂的时空依赖,但是在识别性能方面很难扩展;而双流网络将视频分成运动流和外观流,由于能轻松使用新的深度网络,所以性能逐渐超过时空卷积,但是双流卷积忽视了视频的长时时序结构,在测试阶段分别对采样的一帧或堆叠的几帧进行识别,然后取平均来得到最终的结果,但这种时序的平均不一定能建模复杂的时空结构,以下图篮球投篮为例,给定视频的少数几帧,很有可能与其他的动作,如跑、运球、挑、扔等混淆,使用late fusion或者平均需要视频帧都属于相同的子动作来分配给不同的类别,所以不是一个最优方案,我们需要的是一个全局特征描述子,能对整个视频进行集成,包括场景的外观和人的动作,不需要每帧都分配一个单独的动作类别。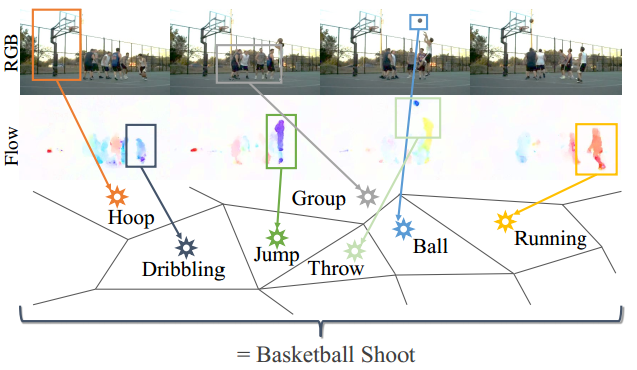
所以,本文提出了ActionVLAD模型,核心是NetVLAD集成层的时空扩展,我们将新的层成为ActionVLAD。在扩展NetVLAD时带来了两个挑战:将不同时间frame-level特征整合为video-level表示的最好的方法是什么;如何组合来自不同stream的信号。
Video-level双流结构
可训练时空集成
假设有xi, t,一个D维的局部描述子,提取自一段空间位置i属于{1…N}和帧t属于{1…T}的视频,我们想在时间和空间中集成整个视频的描述子,同时保存他们的信息内容,做法如下:首先将描述空间RD拆成K个cell,拆解方法是使用由锚点{ck}表示的K个动作词词汇,如下图c所示。下图是为一个有不同特征的集合进行不同pooling策略的结果,里面的点对应视频的特征,不同的颜色对应不同的子动作,a和b适用于比较类似的特征,不能充分地捕获特性的完整分布;c中的表示对外观和运动特征进行了聚类,并从最近的聚类中心集成他们的残差。
每个视频描述子xi, t分配给其中一个cell,并用一个残差向量xit-ck表示,这个残差向量记录了描述子和锚点之间的差异,然后计算整个视频残差向量的和,如以下公式表示,其中xit[j]和ck[j]是描述子xit和ck的第j个元素,alpha是一个可调整的超参,公式中第一项表示将描述子xitsoft-assignment到第k个cell上,第二项是描述子与cell k的锚点之间的残差,两个求和符号表示沿时间和空间集成,输出矩阵V,第k列表示在第k个cell中集成的描述子,然后对每列数据进行内部归一化,堆叠和L2归一化,从而得到一个整个视频单独的描述子v属于RD
以上公式的来源是想用残差向量记录提取的描述子与用锚ck表示的典型动作(或子动作)的差异,然后通过在每个cell内部计算和来将整个视频的残差向量集成,所有的参数,包括特征提取、动作词{ck}和分类器,都是以端到端的方式共同学习的,公式1中的时空结合方法是可微的,允许将错误的梯度反向传播给低层,这里的集成方法是NetVLAD在时空方面的扩展,但是我们是沿着时间t进行求和,我们将这个沿时空的扩展称为ActionVLAD。
以上集成方法与平均/最大pooling的区别在于,后者将整个点的分布描述为一个单独的描述子,对于表示一个包含多个子动作的视频来说是次优的,而以上集成方法通过将描述子空间分成多个cell,并在每个cell中进行pooling,来表示带有多个子动作的描述子的整个分布。理论上,在描述子map和pooling操作之间的隐层,也会在pooling之前将描述子空间分成两个空间(通过使用ReLU),但是,事实证明很难训练一个维度高达KD=32768的隐层。我们假设ActionVLAD框架施加了很强的正则化约束,使得在有限的训练数据下学习这样大型的模型是可行的(就像动作分类一样)。
集成哪一层?
理论上,上面提到的时空集成层应该能放在网络的任一level,来pool对应的feature map,所以需要比较不同的组合,基础的双流网络结构是VGG-16,这里考虑只有外观stream,但是在下一部分讨论组合外观和运动stream的不同方法。
双流网络首先使用所有视频的所有帧训练一个frame-level的分类器,在测试时,平均化T个平均采样的帧的预测结果。我们使用这个基础网络(在frame-level上预训练)作为一个特征生成器,从不同的帧提供输入给可训练的ActionVLAD的pooling层,而进行pool的层,我们考虑两种选择,首先考虑pool网络中FC层的输出,视频中每T帧被表示为1*1的空间feature map,维度为4096,也就是为视频中每T帧pool一个4096维的描述子;其次,考虑pool卷积层的特征(考虑conv4_3和conv5_3),对于conv5_3,14*14的空间feature map,每T帧有512维描述子,所以从每T帧中pool196个512维的描述子,而实验证明,在最高的卷积层进行pool的性能是最好的。
如何组合光流和RGB stream?

ActionVLAD也能用来pool不同stream的特征,不同stream有不同的输入模式,在这里我们考虑外观和运动stream,但是理论上可以pool任意数量的其他stream,如warped flow或者RGB差异。要组合外观和运动stream有很多种方法,这里我们只研究最明显的一种。
在合并的外观和运动之上的单个ActionVLAD层(Concat Fusion)
这里我们合并外观和输出stream的输出feature map,将单个的ActionVLAD层放在合并的feature map之上,如上图a所示,这允许使用外观和运动特征之间的关系来构建codebook。
在所有外观和运动之上的单个ActionVLAD层(Early Fusion)
使用一个单独的ActionVLAD层来pool所有来自外观和运动stream的特征,如下图b所示,这鼓励模型为外观和运动特征学习一个单独的描述子空间xij,使用了特征中的冗余。
Late Fusion
这个方法如图c所示,follow外观和运动最后一层特征的加权平均的标准测试实践,两个stream有各自单独的ActionVLAD层,这使得两个ActionVLAD层为每个输入模式学习对应特别的表示。
实现细节
在以上提到的ActionVLAD表示之上,我们使用了单层的线性分类层,K=64,alpha=1000,因为输出特征维度可能会比较大,我们使用0.5的dropout来避免在小的分类数据库上过拟合,loss为cross-entropy,通过softmax得到概率,将ActionVLAD参数{ck}解耦,xij是用来计算soft assignment和残差向量。
每个视频我们使用T=25帧(光流和RGB都是)来学习和评估视频表示,光流是使用10个现需的x,y方向的光流图来表示,所以输入为20维。因为视频是在video-level训练,由于有限的GPU资源和CPU处理能力,我们每次迭代只fit较少的视频,为了保持合理的batch size,我们通过平均化不同GPU迭代的梯度来缓慢更新,以5.0的L2归一化来clip梯度,通过随机crop/flip所有的RGB和光流帧来扩增数据,优化器使用Adam,以两步法来训练模型。第一步,初始化和固定VLAD聚类中心,只训练线性softmax分类,学习率=0.01;第二部,联合finetune线性分类和ActionVLAD聚类中心,学习率=10-4,实验表明这种方法提高了验证的精度,表明ActionVLAD确实适应聚类来更好地表示视频。当用conv5_3训练ActionVLAD,我们保持conv5_1之前的层固定,避免在小的数据库上过拟合,这也帮助占用少的GPU资源和快速训练。
实验
本次实验用到的数据库是UCF-101和HMDB51,评估标准和训练/测试split与THUMOS13挑战赛相同,我们使用split 1作为ablative分析,并报告所有3个split的平均值作为最终的结果。最后,还在未剪辑数据库Charades上进行评估,因为数据库中一个视频会有多个标签,所以评估方法使用mAP和wAP(weighted average precision),每一类的AP由类别的大小加权。



和混合方法")

